
基于K均值的Scala星火图像分割
我遵循一个教程(从一本书),以实现K均值算法的图像分割使用火花。但是实现是用Python完成的。我认为在Scala上实现它会更好。
但我不能用分割来重建图像。
我正在尝试这张图像,来自癌症成像档案馆(TCIA) (256x256):

这是我的密码:
val spark = SparkSession.builder().appName("mriClass").master("local[*]").getOrCreate()
val mri_healthy_brain_image = "src/main/resources/datasets/clustering/data/mri-images-data/mri-healthy-brain.png"
val image_df = spark.read.format("image").load(mri_healthy_brain_image).select(col("image.*"))
image_df.show
image_df.printSchema
import spark.implicits._
val data = image_df.rdd.collect().map(f => f(5))
val data_array: Array[Byte] = data(0).asInstanceOf[Array[Byte]]
val transposed_df = spark.sparkContext.parallelize(data_array).map(f => Image(f)).toDF
transposed_df.show
val features_col = Array("data")
val vector_assembler = new VectorAssembler()
.setInputCols(features_col)
.setOutputCol("features")
val mri_healthy_brain_df = vector_assembler.transform(transposed_df).select("features")
val k = 5
val kmeans = new KMeans().setK(k).setSeed(12345).setFeaturesCol("features")
val kmeans_model = kmeans.fit(mri_healthy_brain_df)
val kmeans_centers = kmeans_model.clusterCenters
println("Cluster Centers --------")
for(k <- kmeans_centers)
println(k)
val mri_healthy_brain_clusters_df = kmeans_model.transform(mri_healthy_brain_df)
.select("features","prediction")
val image_array = mri_healthy_brain_clusters_df.select("prediction").rdd.map(f => f.getAs[Int](0)).collect()最后,image_array包含65536个位置,每个位置都包含自己的分类。
当将图像加载到Dataframe时,我认为spark将简单地将图像矩阵转换为一维数组,这是DF中的二进制类型行。
考虑到这一点,我很简单地获得image_array并在256x256图像中进行转换
我用地图预定义了分类颜色:
val colors:Map[Int,Int] = Map(
0 -> 0x717171, //gray
1 -> 0x0074FF, //light blue
2 -> 0x95FFDF, //cyan
3 -> 0xFF3333, //red
4 -> 0x0058B6, //blue
5 -> 0xE2CE06, //yellow
6 -> 0xDB06E2, //pink
7 -> 0x67C82C, //green
8 -> 0x8136DC, //purple
9 -> 0x356F07, //darkgreen
10 -> 0xE5A812 //orange
)使用这个函数生成图像:
def generateImage(img: BufferedImage, image_array: Array[Byte]): BufferedImage = {
// img is the original image
// obtain width and height of image
val w = img.getWidth
val h = img.getHeight
if ( w*h != image_array.size)
throw new IllegalArgumentException("image array does not fit the provided image");
// create new image of the same size
val out = new BufferedImage(w, h, BufferedImage.TYPE_INT_RGB)
var s = 0
for (x <- 0 until w)
for (y <- 0 until h){
out.setRGB(x, y, colors(image_array(s).toInt))
s +=1
}
out}
但是我得到的图像是:

我可以肯定地说,我的聚类管道是正确的,因为它符合书中的结果。
但我不确定星火是否在分类后对Dataframe上的字节顺序排序,可能会破坏结果。
有人能告诉我我哪里做错了吗?
提前谢谢
回答 1
Stack Overflow用户
发布于 2019-09-20 10:13:52
我发现图像数据是如何在ImageSchema中组织的。图像数据表示为具有由模式字段指定的尺寸形状(高度、宽度、nChannels)和t类型数组值的三维数组。数组按行大顺序存储(大多数情况下按行向BGR存储)。
由于我对Open没有任何经验,并且需要更多的时间来理解重建图像的基本原理,所以我决定使用ImageIO读取图像,将每个RGB信息存储在一个数组上,并从其中创建一个DataFrame。
然后,我使用了前面描述的相同的过程,使用KMeans分类器,用一幅带有肿瘤的图像生成预测,并以相同的顺序写入字节。
我现在得到的结果是:
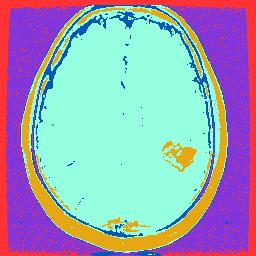
你可以在这里找到我的完整代码:
https://stackoverflow.com/questions/57384772
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号