
用confusionMatrix计算查全率、召回率和F分
我们开发了一种算法,用于检测加速度计数据中每台电阻运动机重复次数。人们总是每台机器重复10次,每次2次。
N人x 10次重复x2组=执行的总次数。
现在,我想从precision包中用confusionMatrix计算confusionMatrix、recall和f-score。
我创建了一个xlsx文件,其中两行表示真实(上行)和算法预测的重复次数(下行),如图中所示:

我编写了以下代码:
reps_prec_phone1<- read.xlsx("Reps_for_Precision_Recall_FSCORE.xlsx", sheet = "2Vec_Phone1", startRow = 0, colNames = FALSE)
reps_prec_pred_phone1<-as.factor(reps_prec_phone1[1,])
reps_prec_real_Phone1<-as.factor(reps_prec_phone1[2,])
result_phone1 <- confusionMatrix(reps_prec_pred_phone1, reps_prec_real_Phone1, mode="prec_recall")结果如下:
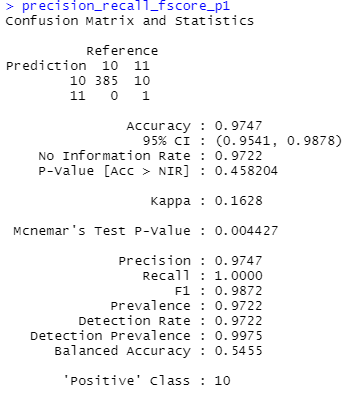
正如您在confusionMatrix中看到的,计算了385组(1组由10次重复组成),而不是3850重复。现在我想知道,在方法上,如何让confusionMatrix来计算重复的次数而不是集合的数量。
在我的例子中,错误率是1-Accuracy = 2.5%。As 1组由10个重复组成。由于设置与重复是10的一个因素,我可以简单地除以10的错误率,并重新计算精度1-0.0025 = 0.9975。然而,
- 有人知道如何用
confusionMatrix解决这个问题吗?
提前感谢您的脑力和经验!
回答 1
Stack Overflow用户
发布于 2019-08-06 15:33:31
有个理论上的错误。
建立一个混淆矩阵来比较给定的观测值和预测值,R将您的数据转换为因子,然后将您的值{10,11}解释为该因子的级别,而不是数字值,然后R对关联进行计数。简单地说,你对什么是混淆矩阵有错误的理解。
而且,任何模型都会执行有偏差的预测,因为您有非常不平衡的数据,简而言之,没有什么可预测的。
那么,您就没有编程问题了--更多的是理论问题。访问Stack Exchange以澄清您的想法。
https://stackoverflow.com/questions/57378413
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号