
Google节点带宽
我正在服务上部署我的集群。它已经有几个节点了。另外,我需要使用Google中的GPU的服务器来使它与我的集群一起工作。GPU实例不断地处理传入流量(带宽应该达到1Gb/s),并在集群节点上发送结果(带宽应该比传入带宽还要多)。
在这个项目中,对我来说最关键的事情是:
1)簇内节点间的带宽;
2)节点与GPU服务器之间的带宽;
3) GPU服务器与世界之间的带宽;
4)节点与世界之间的带宽。
在下载和上传两个节点时,每个节点的最小合适带宽为1GB/s。在进行速度测试时,它显示了下载速度100-680 Mb/s和相同节点的上传速度67-138 Mb/s (下面的截图是在30秒内完成的)。因此,目前的带宽太小和不稳定。但是我需要稳定的带宽,从1GB/s开始。
我试图在Google中找到任何关于带宽的技术规范或价格。但是,在技术规范中,只有CPU/GPU/RAM/磁盘,没有带宽。而且在文档上,每个月的流量只有价格。
TL;DR:
如何为每个集群节点、GPU实例和任何其他Google虚拟机设置稳定的1GB/s或更多带宽?Google中是否有提供超过1GB/s的带宽的服务?谷歌云有什么解决方案/服务,如何处理大量的互联网流量?
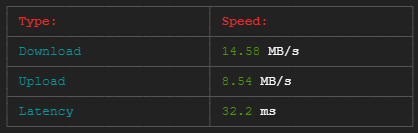
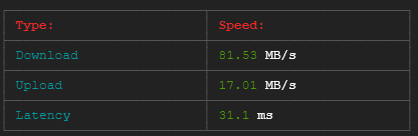
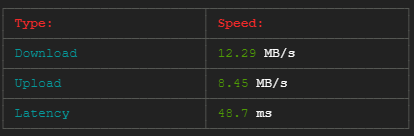
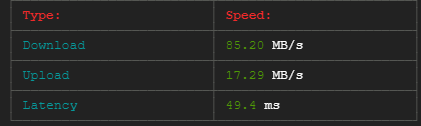
速度测试是通过以下方式进行的:
npx speedo-cli回答 3
Stack Overflow用户
发布于 2019-08-08 06:13:57
没有真正的保证,特别是当涉及到GCP以外的网络的流量时。不过,为了最大限度地利用带宽,您可以做一些事情:
- 增加每个实例的CPU核心数: caps取决于虚拟机实例的vCPU数量。每个核心都有一个2 Gbit/秒(Gbps)的峰值性能上限。每增加一个核心就会增加网络上限,理论上每台虚拟机最多可达到16 Gbps。来源
- Note that the `2 Gbps per vCPU` cap represents a theoretical limit using internal networks: The cap is a limit that can't be exceeded and doesn't indicate the actual throughput of your egress traffic. There is no guarantee that your traffic will achieve the maximum throughput, which depends on many factors other than the cap. [source](https://cloud.google.com/vpc/docs/advanced-vpc#measurenetworkthroughput)
- 如果VM之间的通信量(即问题中的案例1和2),请确保VM位于同一区域的中,并且您使用的是内部IP: 无论何时,当您在VM之间传输数据或通信时,都可以通过使用内部IP进行通信来达到最大的性能。在许多情况下,速度的差异可能是巨大的。来源
- Check [this answer](https://serverfault.com/a/870498) on how to measure network bandwidth between VMs using `iperf`.
- 对于高级用例,您可以在VM中尝试微调TCP窗口大小。
最后,一个基准观察到the GCP network throughput is 81x more variable when compared to AWS。当然,这只反映了一个基准,但您可能会发现,值得自己测试其他提供者。
Stack Overflow用户
发布于 2020-01-16 21:36:16
自从亚历克西的回答,有一些变化的每VM出口帽/油门。它仍然被计算为2 Gbit/s *NumberOfvCPU,但是最大值现在是32 Gbit/s (当VM是用skylake的min_cpu_platform或更高的版本创建的),对于有2个或更多的vCPUs的VM,至少有10 Gbit/s。
我不清楚速度测试的端点是什么,但是TCP连接吞吐量的(许多)限制之一是:
吞吐量<= WindowSize / RoundTripTime
人们会期望GPU实例和节点将彼此靠近,但这种限制可能会对GPU实例和节点产生影响。
除此之外,了解可变吞吐量发生的情况可能需要数据包跟踪,肯定是在发送端,最好也是在接收端。在这种情况下,每个数据包的前96个字节就足够了。这将是一个支持组织所要求的事情之一。
Stack Overflow用户
发布于 2019-08-04 20:45:40
我担心你不能在互联化的基础设施上有任何捆绑承诺。如果您拥有(大量)现金,那么在同一租户上使用您架构的所有部分都可以帮助解决外部寄生虫问题。但是在这种情况下,没有网络带宽的承诺。而且,目前,这个解决方案不支持GPU。
https://stackoverflow.com/questions/57304432
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号