
我如何提供一个关系提取数据集,包括元组,用于临时推断使用名称实体识别空间?
我如何提供一个关系提取数据集,包括元组,用于临时推断使用名称实体识别空间?
提问于 2019-07-31 13:30:23
我有大约7.000句句子,其中我做了一个精炼的名称-实体-识别(即,特定的实体)使用SpaCy。现在我想做关系提取(基本上是因果推理),我不知道如何使用NER来提供训练集。
据我所知,有一种不同的方法来执行关系提取:
- 1)手写模式
- 2)有监督的机器学习
- 3)半监督机器学习。
因为我想使用有监督的机器学习,所以我需要训练数据。
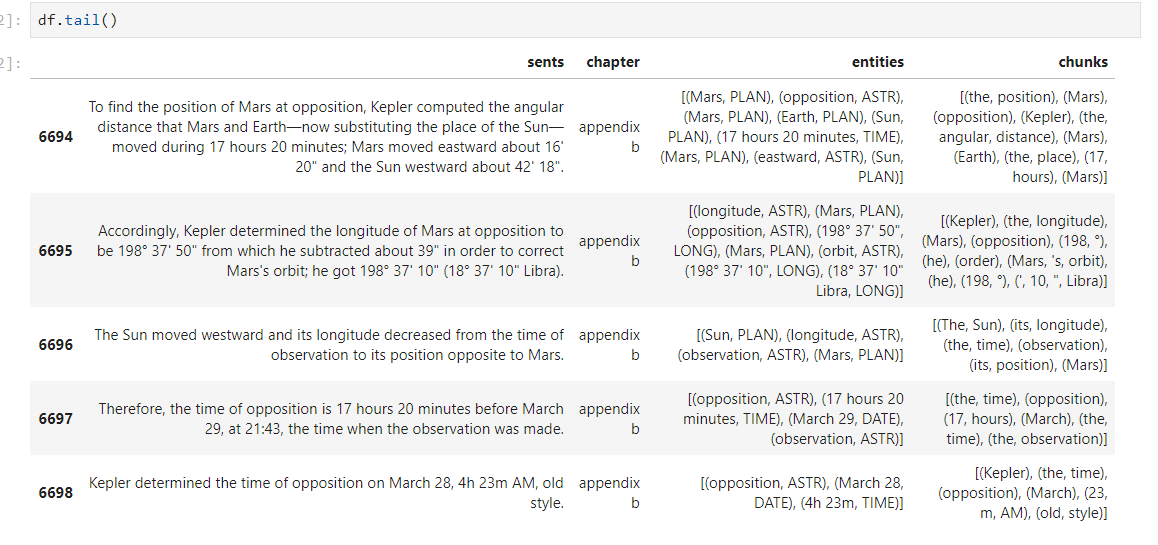
如果有人能给我指路,那就太好了,非常感谢。这里是我的数据框架的屏幕拍摄,实体是由一个定制的spaCy模型提供的。我可以访问每个句子的语法依赖和部分词性标记,如spaCy提供的:
回答 1
Stack Overflow用户
发布于 2019-08-05 19:25:49
似乎你的数据集是一种技术性的写作,非常好的结构,所以也许部分语音标记就足以完成你想要的提取。
我建议您阅读本文,并了解使用开放信息抽取中的识别关系的基于pos标记的模式。
下面这段代码用语音部分标记发送,然后查找与称为ReVerb模式匹配的序列。
import nltk
verb = "<ADV>*<AUX>*<VBN><IN|PART>*<ADV>*"
word = "<NOUN|ADJ|ADV|DET|ADP>"
preposition = "<ADP|ADJ>"
rel_pattern = "( %s (%s* (%s)+ )? )+ " % (verb, word, preposition)
grammar_long = '''REL_PHRASE: {%s}''' % rel_pattern
reverb_pattern = nltk.RegexpParser(grammar_long)
sent = "where the equation caused by the eccentricity is maximum."
sent_pos_tags = nltk.tag.pos_tag("where the equation caused by the eccentricity is maximum".split())
for x in reverb_pattern.parse(tags):
if isinstance(x, nltk.Tree) and x.label() == 'REL_PHRASE':
rel_phrase = " ".join([t[0] for t in x.leaves()])
print(rel_phrase)有一点遗漏了,那就是找出最接近模式左右的名词短语,但我把它作为练习。我还用一个更详细的例子编写了一个博客帖子。希望能帮上忙。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57291975
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号