
如果熊猫有重复的值,如何使用它们合并行?
如果熊猫有重复的值,如何使用它们合并行?
提问于 2019-07-29 23:45:09
我的数据有一个特殊的例子,我在任何文档或堆栈中都找不到答案。
我想要做的是基于‘MPN’列(而不是Vehicle列)合并副本。
在许多行中都会有MPN的重复,如第一个图像所示。
显然,我希望删除具有相同MPN的重复行,但是将图像1中显示的三行的分类值合并到一个单元格中,如图2所示,这将是我编码后想要的结果。
我想要的是:能够根据包含重复MPN的行合并和删除重复项,并将它们合并为一个,同时保留由冒号分隔的类别。
看我的前后图像,以更清楚地理解。
我还使用Python3.7从csv文件(用逗号隔开)编写这段代码。
以前:
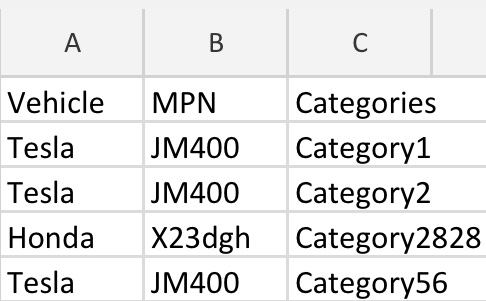
合并后的:
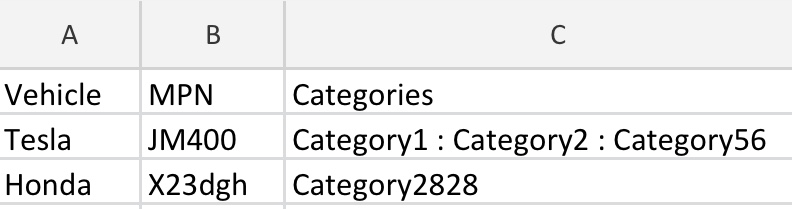
我该如何解决这个问题?
回答 1
Stack Overflow用户
发布于 2019-07-30 00:26:14
假设df持有csv数据。首先根据公共列(Vehicle和MNP)进行分组,并在类别列上创建和更新公共分隔字符串。
df['x'] = df.groupby(['foo','bar'])['x'].transform(lambda x: ':'.join(x))第二次删除重复项
df.drop_duplicates()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57262569
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号