
根据节点的数目将数据拆分
根据节点的数目将数据拆分
提问于 2019-07-25 10:13:50
我试图根据(集群的)节点数来拆分我的数据文件,
我的数据看起来像:
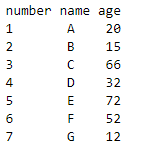
如果我有node=2,dataframe.count=7:
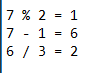
因此,要应用迭代方法,拆分的结果将是:

我的问题是:我该怎么做?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-07-25 23:27:08
您可以使用其中一个rdd分区函数来完成(请看下面的代码),但我不建议将其作为
只要你没有完全意识到你在做什么,也不知道为什么你要这么做。通常(或者对大多数用户来说更好),最好让spark处理数据分布。
import pyspark.sql.functions as F
import itertools
import math
#creating a random dataframe
l = [(x,x+2) for x in range(1009)]
columns = ['one', 'two']
df=spark.createDataFrame(l, columns)
#create on partition to asign a partition key
df = df.coalesce(1)
#number of nodes (==partitions)
pCount = 5
#creating a list of partition keys
#basically it repeats range(5) several times until we have enough keys for each row
partitionKey = list(itertools.chain.from_iterable(itertools.repeat(x, math.ceil(df.count()/pCount)) for x in range(pCount)))
#now we can distribute the data to the partitions
df = df.rdd.partitionBy(pCount, partitionFunc = lambda x: partitionKey.pop()).toDF()
#This shows us the number of records within each partition
df.withColumn("partition_id", F.spark_partition_id()).groupBy("partition_id").count().show()输出:
+------------+-----+
|partition_id|count|
+------------+-----+
| 1| 202|
| 3| 202|
| 4| 202|
| 2| 202|
| 0| 201|
+------------+-----+页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57199546
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号