
如何使用geonames ID丰富地方
如何使用geonames ID丰富地方
提问于 2019-07-23 17:38:27
我有一个位置列表,我可以用地理名称的ID来充实这些地方。由于geonames在默认情况下是嵌入到WikiData中的,所以我选择使用WikiData端点直接通过SPARQL。
我的工作流程:
- 我已将excel文件导入OpenRefine并创建了一个新项目。
- 在OpenRefine中,我创建了我的图形,然后以RDF/XML的形式下载了它。这里有一个快照: ">http://localhost:3333/0"> A re5A1CE163-105 F-4BAF 8BF9
- 然后,我将RDF文件导入本地graphDB,并运行了联邦查询:
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT *
WHERE {?place <http://purl.org/NET/cidoc-crm/core#P1_is_identified_by> ?value;
rdfs:label ?label_geo.
SERVICE <https://query.wikidata.org/sparql> {
?value wdt:P31/wdt:P279* wd:Q515;
rdfs:label ?label;
wdt:P1566 ?id_value.
}
}
limit 10没有结果。
输出应该如下所示:
|-----------------------|------------------|---------------|
| Oggetto | Place | GeonamesID |
|-----------------------|------------------|---------------|
|5A1CE163-105F-4BAF 8BF9| Aïre |11048419 |
|-----------------------|------------------|---------------|有什么建议吗?
非常感谢。
回答 1
Stack Overflow用户
发布于 2019-08-20 17:45:35
我通过客户直接解决了这个问题
在这里我的管道:
- 我已经创建了一个带有地名列表的Excel表
- 我构建了一个Python脚本,它使用excel表中的值作为查询参数,并将输出保存到一个.txt文件中。例如,A re,https://www.geonames.org/11048419
import pandas as pd
import requests
import json
import csv
url = 'http://api.geonames.org/searchJSON?'
#Change df parameters according to excel sheet specification.
df = pd.read_excel('grp.xlsx', sheet_name='Foglio14', usecols="A")
for item in df.place_name:
df.place_name.head()
#Change username params with geonames API username
params ={ 'username': "XXXXXXXX",
'name_equals': item,
'maxRows': "1"}
e = requests.get(url, params=params)
pretty_json = json.loads(e.text)
with open("data14.txt", "a") as myfile:
writer = csv.writer(myfile)
for item in pretty_json["geonames"]:
#print("{}, https://www.geonames.org/{}".format(item["name"], item["geonameId"]))
writer.writerow([item["name"], "https://www.geonames.org/{}".format(item["geonameId"])]) #Write row.
myfile.close()- 我已经复制了excel工作表B列中的.txt文件的输出。
- 然后,我将输出值拆分为两列。例如。
|---------------------|-----------------------------------|
| ColA | ColB |
|---------------------|-----------------------------------|
| Aïre | https://www.geonames.org/11048419 |
|---------------------|-----------------------------------|- 由于地名和所获得的结果之间没有1:1的对应关系,所以我已经对齐了这些值。
- 在excel表中,我创建了一个新的空列B
- 在B列中,我编写了公式:
=IF(ISNA(MATCH(A1;C:C;0));"";INDEX(C:C;MATCH(A1;C:C;0)))和我将公式迭代到列表的末尾 - 然后我创建了一个新的空列C
- 在C列中,我编写了公式:
=IFERROR(INDEX($E:$E;MATCH($B1;$D:$D;0));"")和我将公式迭代到列表的末尾
最后的结果如下:
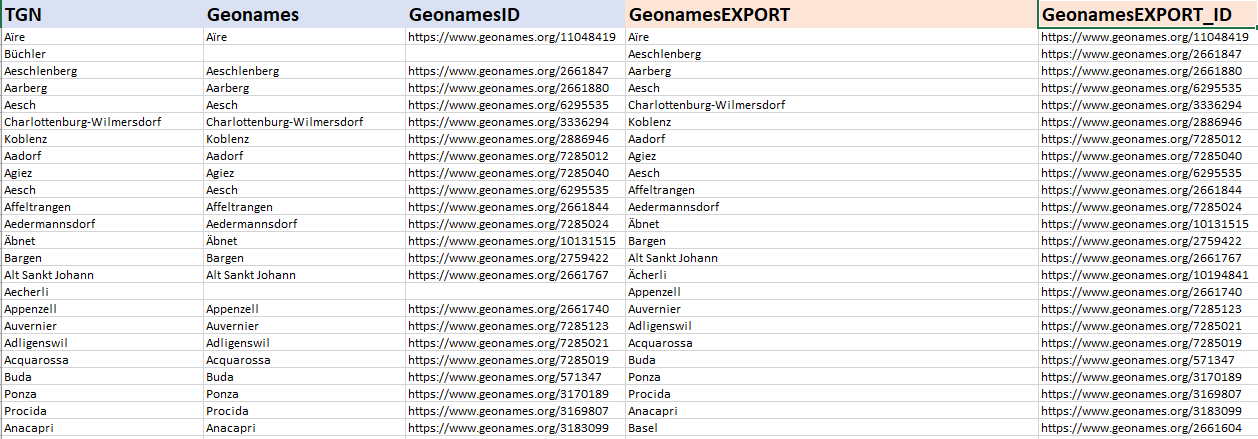
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57169513
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号