
bluedata写访问问题: hdfs_access_control_exception:权限被拒绝
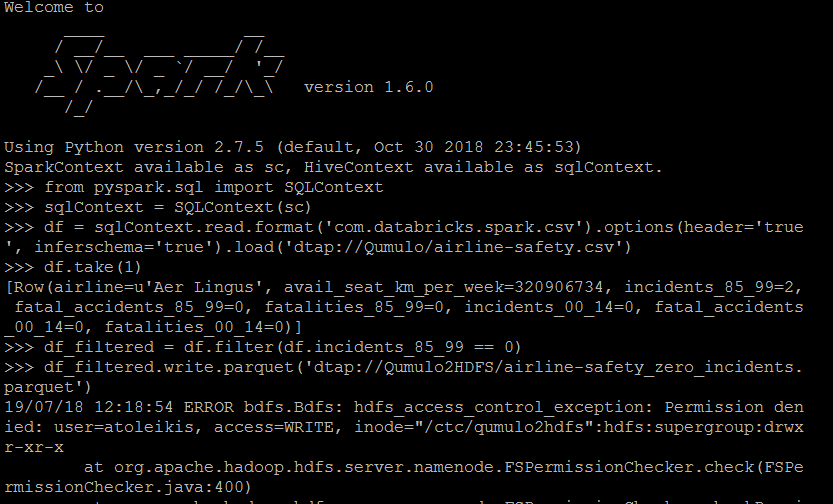
我们有BlueData 3.7运行,我启动Cloudera5.14集群与火花和纱线。我从每个NFS的Qumulo获取一个csv文件,每个DTAP将一个csv文件放入Spark容器中,只需执行一个小的过滤器,并将结果保存为每个DTAP的parquet文件,然后保存到我们的外部HDFS Cloudera集群中。除了将文件写入外部HDFS集群之外,一切都正常。我完全可以从HDFS中读取每个DTAP,并将每个DTAP写入Qumulo。只是每个DTAP写入HDFS不起作用。我得到的消息是,我的用户(在AD组的EPIC中)没有编写权限(如您在下面的图片中看到的)。
知道为什么吗?HDFS的DTAP不配置为只读。所以我希望它是读和写的。
注意:
- 我已经检查过Cloudera的访问权限了。
- 我检查了BD集群中的AD凭据。
- 我可以从HDFS读取这些凭据。
这是我的代码:
$ pyspark --master yarn --deploy-mode client --packages com.databricks:spark-csv_2.10:1.4.0
>>> from pyspark.sql import SQLContext
>>> sqlContext = SQLContext(sc)
>>> df = sqlContext.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load('dtap://TenantStorage/file.csv')
>>> df.take(1)
>>> df_filtered = df.filter(df.incidents_85_99 == 0)
>>> df_filtered.write.parquet('dtap://OtherDataTap/airline-safety_zero_incidents.parquet')错误信息:
hdfs_access_control_exception:前置任务被拒绝
回答 1
Stack Overflow用户
发布于 2019-07-22 08:48:00
有了BlueData支持人员的帮助,我可以解决这个问题!我得到了这样的信息:“如果未应用ACL规则,那么属性dfs.namenode.acls.enabled可能不会设置为true。请将其更改为”已启用并重新启动namenode“以启用ACL,否则配置的ACL不会生效。我这样做了,仍然无法使用写命令访问HDFS。
我还必须更改HDFS本身对我的文件夹的访问权限来编写权限。问题解决了。
https://stackoverflow.com/questions/57142130
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号