
将一系列深度映射和x,y,z,theta值转换为三维模型
我有一个四转子,它在x,y,z轴上飞行,知道它的x,y,z位置和沿x,y,z轴的角位移。它捕获了一个不断的图像流转换成深度图(我们可以估计每个像素与摄像机之间的距离)。
如何编程将这些信息转换为环境的三维模型的算法?也就是说,我们如何从这些信息生成虚拟3D地图?
下面是一张图片,它说明了四转子捕捉的是什么(顶部),以及将图像转换成什么来输入三维映射算法(底部)。
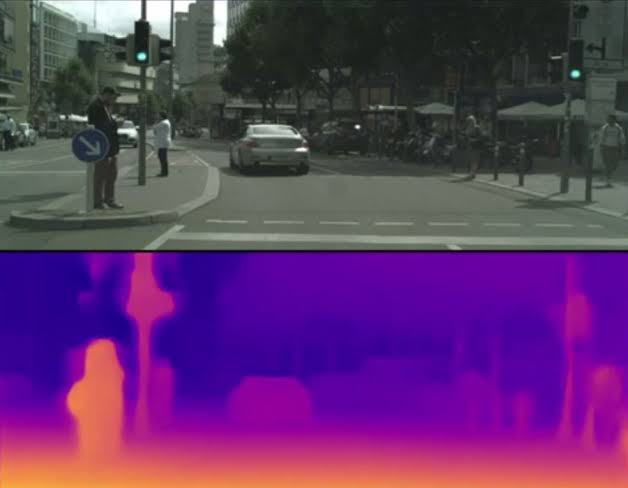
让我们假设这张照片是从x,y,z坐标(10,5,1)的相机上拍摄的,在某些单位中,角位移为90,0,0度,与x,y,z轴相关。我想要做的是把这些照片坐标元组转换成一张区域的三维地图。
编辑1 on 7/30:一个明显的解决方法是利用四转子wrt到x、y和z轴的角度和距离图来计算任何有三角障碍物的笛卡尔坐标。我想我可能会写一种算法,用这种方法用概率方法绘制一个粗略的3D地图,可能会将它矢量化,使它更快。
然而,我想知道是否有什么根本不同的、希望更快解决这一问题的办法?
回答 1
Stack Overflow用户
发布于 2019-08-04 14:12:04
只需将数据转换为笛卡儿并存储结果..。您已经知道输入数据的拓扑结构(数据点之间的空间关系),那么这可以直接映射到网格/曲面,而不是PCL (这需要三角剖分或凸包等等)。
您的图像显示您已经知道拓扑结构(相邻像素在3D中也是相邻的.)因此,您可以直接构建网格三维曲面:
- 对齐RGB和深度2D地图. 如果还没有这样做,请参见:
- [Align already captured rgb and depth images](https://stackoverflow.com/a/35914008/2521214)
- 转换为笛卡尔坐标系. 首先,我们计算相机局部空间中每个像素的位置:
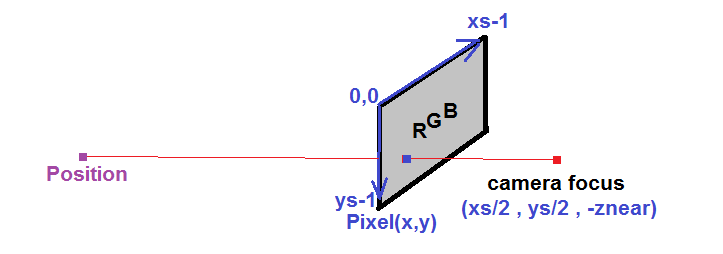
因此,在RGB地图中的每个像素(x,y),我们找出与摄像机焦点的深度距离,并计算出相对于相机焦点point.For的三维位置,我们可以使用三角形相似性:
X= camera_focus.x +(象素x-摄像机_Focus.x)*深度(像素.x,像素.y)/focal_length y= camera_focus.y +(像素.y-照相机_Focus.y)*深度(像素.x,像素.y)/focal_length z= camera_focus.z +深度(像素.x,像素.y)
其中pixel是像素的2D位置,depth(x,y)是对应的深度,focal_length=znear是固定的摄像机参数(确定FOV)。camera_focus是摄像机的焦点位置。通常情况下,相机的焦点在相机图像的中间,znear距离图像(投影平面)很远。
由于这是从移动设备,你需要把它转换成一些全局坐标系(使用您的相机位置和空间定位)。因为这是最好的:
- [Understanding 4x4 homogenous transform matrices](https://stackoverflow.com/a/28084380/2521214)
- 构造网格
由于您的输入数据已经在空间上排序,我们可以直接构建四栅格。简单地说,对于每个像素,取其邻居并形成四角体。因此,如果您的数据
(x,y)中的2D位置按照前面的项目中描述的方法转换为3D(x,y,z),我们可以以返回3D位置的函数的形式编写物联网: (x,y,z) = 3D(x,y) 然后我就可以像这样组成四人小组: 四( 3D(x,y),3D(x+1,y),3D(x+1,y+1),3D(x,y+1) ) 我们可以使用循环: 对于(x=0;x其中xs,ys是地图的分辨率。
如果您不知道相机属性,可以将focal_length设置为任何合理的常数(结果是鱼眼效应和缩放输出),或者从输入数据中推断出它,如:
https://stackoverflow.com/questions/57124699
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号