
K-均值聚类解释
K-均值聚类解释
提问于 2019-07-16 12:11:09
我有三个星系团对图"Av. mon.hrs“,"Sat. Lvl","Last”,并通过下面的代码找到了一个矩阵图。
library("ggplot2") # Expanded plotting functionality over "lattice" package
x<-cbind(HR_left$average_montly_hours,HR_left$satisfaction_level,HR_left$last_evaluation)
kmfit<-kmeans(x,3,nstart=25)
# Find the best 3 clusters using 25 random sets of (distinct) rows in x as initial centres.
pairs(x,col=(kmfit$cluster), labels=c("Av. Mon. Hrs","Sat. Lvl","Last Eval."))上面写着
- 第一组:这组的特征是工作时间低,平均每月工作时间少,满意度中等,最后一次评价较低。
- 第二组:从成对的情节来看,这个组的特点是月薪高,满意度低,评价高。
- 第三组:从成双成对的情节来看,该群体具有月薪高、满意度高、评价高的特点。
但我不明白如何解释这三项发现的配对图。
library(readr)
HR_comma_sep <- read_csv("https://stluc.manta.uqcloud.net/mdatascience/public/datasets/HumanResourceAnalytics/HR_comma_sep.csv")
HR_left<-HR_comma_sep[HR_comma_sep$left==1,]
library("ggplot2") # Expanded plotting functionality over "lattice" package
x<-cbind(HR_left$average_montly_hours,HR_left$satisfaction_level,HR_left$last_evaluation)
kmfit<-kmeans(x,3,nstart=25)
# Find the best 3 clusters using 25 random sets of (distinct) rows in x as initial centres.
pairs(x,col= (kmfit$cluster),labels=c("Av. Mon. Hrs","Sat. Lvl","Last Eval."))回答 1
Stack Overflow用户
发布于 2019-07-16 16:05:55
“每月工作时间”的数量与其他两个变量的比例相差很大,从而使聚类产生偏差。“工作时间”的差异主导了另外两个变量的差异。
通过除以平均值、范围或求z分数来规范每一列.
原始守则:
library(readr)
HR_comma_sep <- read_csv("https://stluc.manta.uqcloud.net/mdatascience/public/datasets/HumanResourceAnalytics/HR_comma_sep.csv")
HR_left<-HR_comma_sep[HR_comma_sep$left==1,]
library("ggplot2")
x_org<-cbind(HR_left$average_montly_hours,
HR_left$satisfaction_level,
HR_left$last_evaluation)
kmfit<-kmeans(x_org, 3, nstart = 25)
pairs(x_org,col= (kmfit$cluster),labels=c("Av. Mon. Hrs","Sat. Lvl","Last Eval."))

重复使用缩放值进行的计算:
x_scaled<-cbind(scale(HR_left$average_montly_hours),
scale(HR_left$satisfaction_level),
scale(HR_left$last_evaluation))
kmfit<-kmeans(x_scaled, 3)
pairs(x_org,col= (kmfit$cluster),labels=c("Av. Mon. Hrs","Sat. Lvl","Last Eval."))
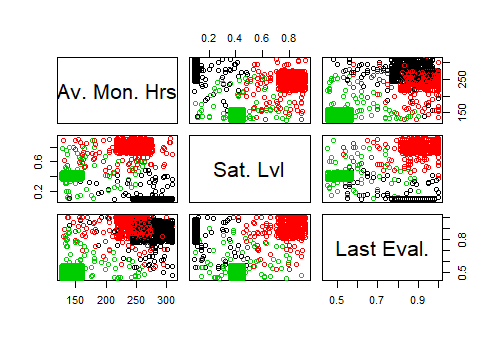
仅使用原始值,根据“月时数”的差异进行聚类,上面的图显示两个簇(黑色和绿色)合并在一起,而且不清楚。
在缩放值和重复聚类之后,现在清晰地显示了3个明显区分的集群(底部图像)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/57056974
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号