
解析PDF并获取头部分信息
解析PDF并获取头部分信息
提问于 2019-07-11 11:13:20
我试图解析PDF的内容。基本上是科研论文。
下面是我想要抓住的那部分:
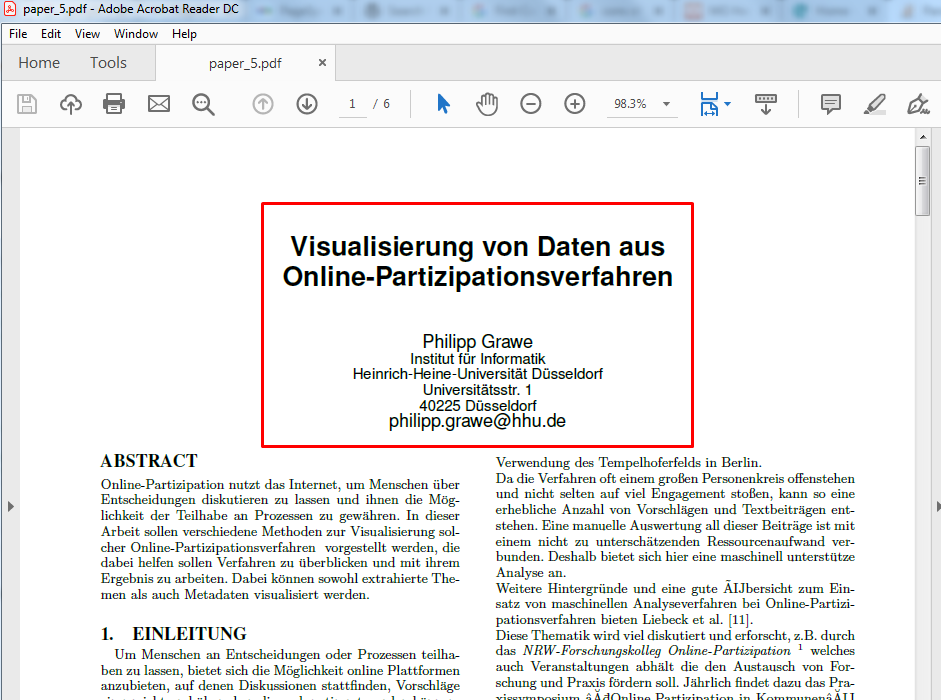
我只需要书名和作者的名字。
我用的是PDF解析库。我能够使用以下代码获取标题部分文本:
function get_pdf_prop( $file )
{
$parser = new \Smalot\PdfParser\Parser();
$pdf = $parser->parseFile( $file );
$details = $pdf->getDetails();
$page = $pdf->getPages()[0];
//-- Extract the text of the first page
$text = $page->getText();
$text = explode( 'ABSTRACT', $text, 2 ); //-- get the text before the "ABSTRACT"
$text = $text[0];
//-- split the lines
$lines = explode( "\n", $text );
return array(
'total_pages' => $details['Pages'],
'paper_title' => $lines[0] . $lines[1],
'author' => $lines[2]
);
}我所做的是,解析第一页的全文,然后以纯文本的形式返回整个文本。由于所需内容位于单词ABSTRACT之前,所以我尝试拆分文本,然后拆分行。
我假设前两行是标题,第三行是作者的名字。到目前为止,就像我在上面的截图中所展示的那样,论文给出了正确的结果。
但是,在下列情况下会出现问题:
- 如果纸标题是单行的话,我就不知道了。因此,我的代码将始终返回前两行纸瓦片。这可能会同时给出标题和作者名为
paper_title - 如果纸标题是三行,这将再次提出问题。
- 如果有一个以上的作者,那么我的代码将不会返回正确的数据。
那么,对于如何有效地从PDF科学论文中获取像论文标题和作者姓名这样的数据,有什么建议吗?我确信在使用LateX工具创建PDF时,它们都遵循相同的模式。有更好的解决办法或线索吗?
请注意,我试图在我的网站上传的文件上这样做。并使用PHP作为服务器端语言。
谢谢
回答 1
Stack Overflow用户
发布于 2019-07-11 13:07:18
您可以尝试使用PDF元数据来检索所需的“字段”(作者、标题、其他.)。我随机尝试了几篇科学论文,它们都有(至少)用于网页、作者和标题的元数据。
PDF解析文档展示了如何做到这一点:
<?php
// Include Composer autoloader if not already done.
include 'vendor/autoload.php';
// Parse pdf file and build necessary objects.
$parser = new \Smalot\PdfParser\Parser();
$pdf = $parser->parseFile('document.pdf');
// Retrieve all details from the pdf file.
$details = $pdf->getDetails();
// Loop over each property to extract values (string or array).
foreach ($details as $property => $value) {
if (is_array($value)) {
$value = implode(', ', $value);
}
echo $property . ' => ' . $value . "\n";
}
?>随机抽取的纸张(var_dump($details))的样本输出:
array(7) {
["Author"]=>
string(18) "Chris Fraley et al"
["CreationDate"]=>
string(25) "2011-06-23T19:20:24+01:00"
["Creator"]=>
string(26) "pdftk 1.41 - www.pdftk.com"
["ModDate"]=>
string(25) "2019-07-11T14:56:29+02:00"
["Producer"]=>
string(45) "itext-paulo-155 (itextpdf.sf.net-lowagie.com)"
["Title"]=>
string(38) "Probabilistic Weather Forecasting in R"
["Pages"]=>
int(9)
}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56987917
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号