
TensorFlow优化器是否学习带有赋值的图中的渐变?
我正在复制Elman网络的原始论文(Elman,1990),以及Jordan网络,称为简单递归网络(SRN)。据我所知,我的代码正确地实现了前向传播,而学习阶段是不完整的。我正在使用TensorFlow的低级API来实现网络.
Elman网络是一种由两层组成的人工神经网络,其中隐藏层被复制为“上下文层”,在下一次向前传播网络时与输入连接。最初,上下文层初始化为activation = 0.5,其固定权重为1.0。
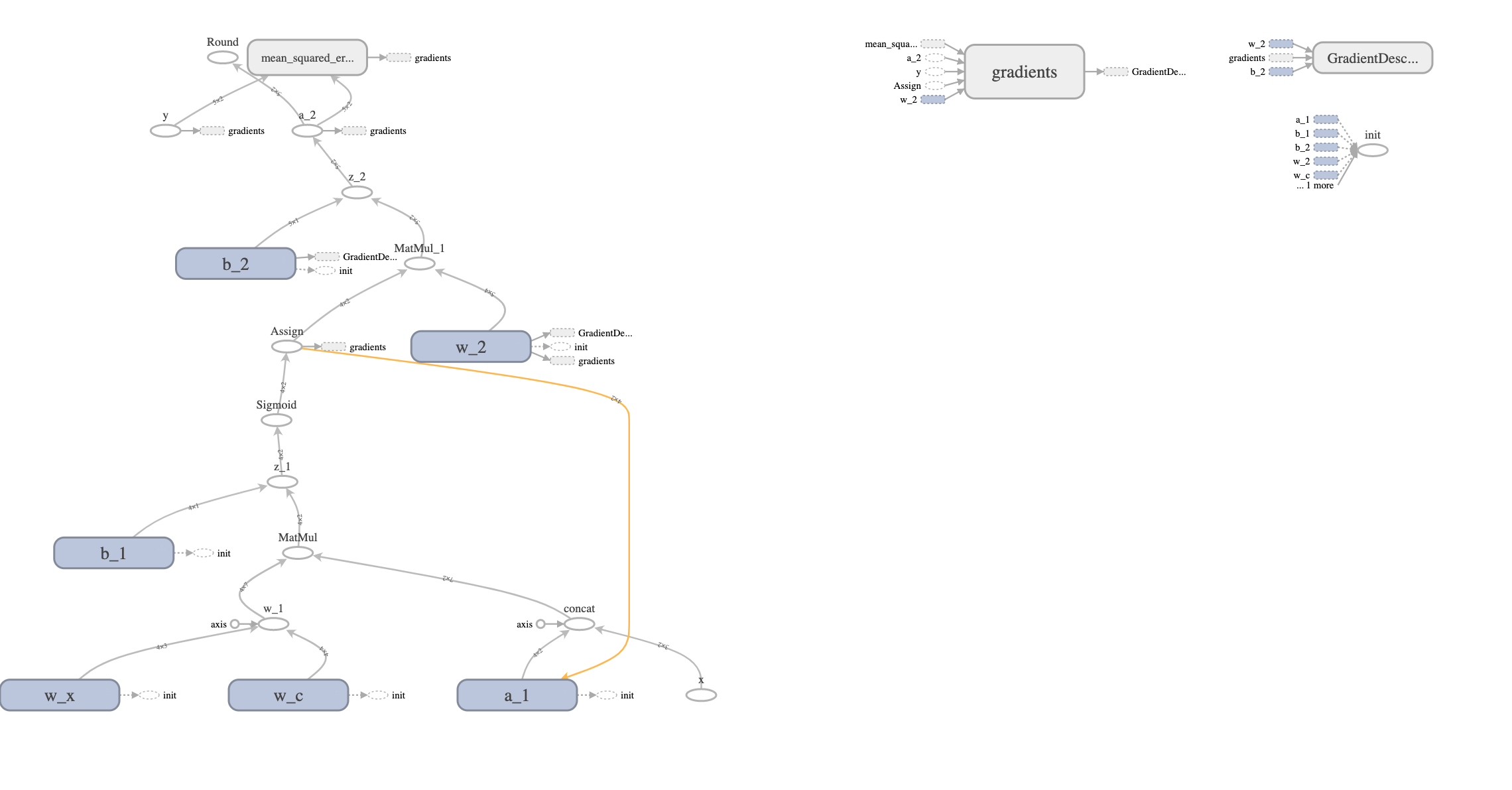
我的问题是梯度的计算,网络的反向传播。在我的代码中,我使用tf.assign使用隐藏层的激活更新上下文单元。在向图中添加赋值操作符之前,TensorBoard显示GradientDescentOptimizer将从图中的所有变量中学习渐变。在我包含此语句之后,渐变将不会显示在赋值“之前”的节点中。换句话说,我希望b_1、w_x、w_c和a_1会出现在优化器学习的梯度列表中,即使在图中有赋值。
我相信我的前向传播实现是正确的,因为我比较了使用tf.assign激活的最终值和使用普通Numpy数组的另一个实现的值。价值是相等的。
最后:这种行为是故意的还是我做错了什么?
正如我所描述的,这里有一个带有网络实现的笔记本:
https://gist.github.com/Irio/d00b9661023923be7c963395483dfd73
参考资料
Elman,J.L. (1990)。及时发现结构。认知科学,14(2),179-211。从https://crl.ucsd.edu/~elman/Papers/fsit.pdf检索
回答 1
Stack Overflow用户
发布于 2019-07-08 09:22:35
不,赋值操作不反向传播渐变。这是故意的,因为给变量赋值不是一种可微性操作。但是,您可能不需要赋值的梯度,而是变量的新值的梯度。您可以使用该梯度,只是不要将其用作赋值操作的输出。例如,您可以这样做:
import tensorflow as tf
my_var = tf.Variable(var_intial_value, name="MyVar")
# Compute new value for the variable
new_my_var = ...
# Make the assignment operation a control dependency
with tf.control_dependencies([tf.assign(my_var, new_my_var)]):
# Passing the value through identity here will ensure assignment is done
# while keeping it differentiable
new_my_var = tf.identity(new_my_var)
# Continue using the value这意味着在反向传播中不使用my_var,因此优化器不会更新它。但是,我认为如果您自己给my_var赋值,那么优化器不应该更新它。
https://stackoverflow.com/questions/56931557
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号