
GTK字符计数与字节索引
在GtkTextBuffer中,
我可以看到GTK+将西里尔字符存储在两个字节中(这让我有点困惑,我认为它存储了UTF-8编码的字符,因此每个字符都必须在一个字节内?)
这导致了一个问题--我在循环中将文本扫描为字符串,我需要根据循环中的索引引用适当的字符位置,但是它们已经没有相应的索引了,因为文本包含西里尔字母。字符数为8310,字符串大小约为11300。
如果我在正在扫描的字符串上使用g_str_to_ascii(),稍后当我在树视图小部件上显示字符串的某些内容时,它会将西里尔字符显示为?的。
我该如何解决这个问题?
G_MODULE_EXPORT void on_textbuffer_changed (GtkTextBuffer* textbuffer, gpointer user_data)
{
GtkTextIter start = {0};
GtkTextIter end = {0};
gchar* text = NULL;
gtk_text_buffer_get_bounds(textbuffer, &start, &end);
text = gtk_text_buffer_get_text(textbuffer, &start, &end, FALSE);
printf("[%i][%i]\n", gtk_text_buffer_get_char_count(textbuffer), strlen(text));
g_free(text);
}这将打印出[1][2],如果我放置西里尔字符和[2][4],如果我放置两个西里尔字符。
这些是西里尔字母"а“(char/dec)的字节:
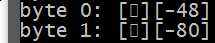
回答 1
Stack Overflow用户
发布于 2019-07-03 20:38:50
还不完全清楚您想要做什么,但是如果您只需要一次处理整个UTF-8字符串,GLib Unicode操作函数可能会有所帮助,例如g_utf_next_char()和g_utf_get_char()。
这并不改变这样一个事实,即字符是Unicode,所以可能是多字节字符。
如果您的目标是能够基于例如匹配的单词修改缓冲区,那么您应该查看GtkTextIter API:例如,您可以使用搜索()获取直接在GtkTextBuffer API中使用的开始和结束项。这样,您就不需要处理实际的字符或字节索引。
https://stackoverflow.com/questions/56877221
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号