
在数据边界寻找峰值
在数据边界寻找峰值
提问于 2019-07-02 16:34:49
我想使用scipy.signal.find_peaks来查找某些2D数据中的峰值,但是函数默认忽略所有边缘峰值(出现在数组左边框或右边框上的峰值)。有没有办法在结果中包括边缘峰?
例如,我希望这段代码:
find_peaks([5,4,3,3,2,3])生产
[0,5]但相反,它产生了
[]回答 2
Stack Overflow用户
回答已采纳
发布于 2020-07-08 17:38:23
查找峰库可以检测边缘。
pip安装查找峰
示例:
X = [5,4,3,2,1,2,3,3,2,3,2,4,5,6]
# initialize with smoothing parameter
fp = findpeaks(lookahead=1, interpolate=5)
# fit
results=fp.fit(X)
# Plot
fp.plot()
# Print the xy coordinates.
# The first and last one in the array are the edges.
print(results['df'])
# x y labx valley peak labx_topology valley_topology peak_topology
# 0 5 1.0 True False 1.0 True True
# 1 4 1.0 False False 1.0 False False
# 2 3 1.0 False False 1.0 False False
# 3 2 1.0 False False 1.0 False False
# 4 1 1.0 True False 1.0 True False
# 5 2 2.0 False False 2.0 False False
# 6 3 2.0 False True 2.0 False True
# 7 3 2.0 False False 2.0 False False
# 8 2 2.0 True False 2.0 True False
# 9 3 3.0 False True 3.0 False True
# 10 2 3.0 True False 3.0 True False
# 11 4 4.0 False False 4.0 False False
# 12 5 4.0 True False 4.0 True False
# 13 6 4.0 False False 4.0 False TrueFit是在平滑的向量上完成的:
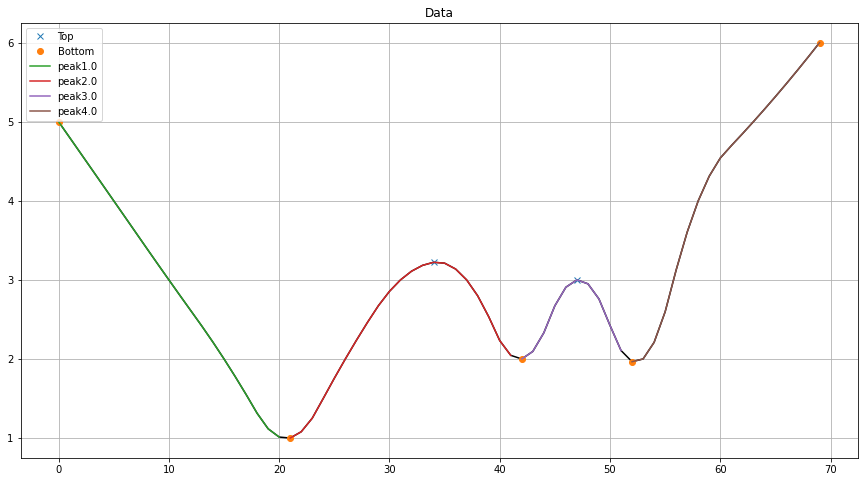
最后的结果被预测回到原来的向量:
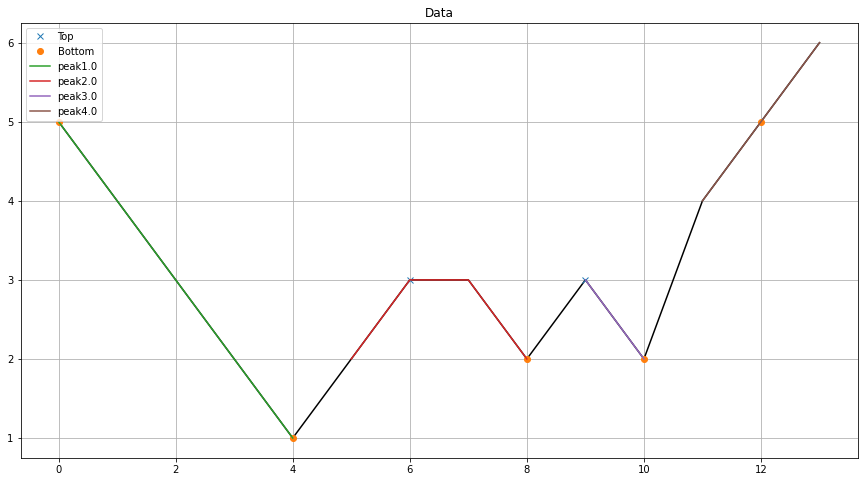
Stack Overflow用户
发布于 2019-07-02 16:53:08
根据find_peaks更详细的用法,我建议在数组的开头和结尾重复数据。
peak_info = find_peaks([4,5,4,3,3,2,3,2])
# correct for additional initial element in auxiliary input array
peaks = peak_info[0] - 1例如,如果设置了find_peaks所需的最小峰值width参数,那么在开始和结束时重复反向数组甚至可能是有意义的。
如果左边和右边的数据值都较低,find_peaks通常只会识别峰值。因此,它也不会识别[5,5,4,3,3,2,3,3]中的任何峰值(即分别重复第一个和最后一个数组元素)。重复数组开头和结尾的第二个和最后一个元素,或者在开始和结束时插入较低的值,就可以将这些边界点识别为峰值。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56856794
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号