
如何在Power中创建连续度量
我试着创造一个连续三次的方法。在这种情况下,我有两个级别的分组查找最大值,然后第三个级别的分组,我希望有平均值。这需要作为一种度量,因为我需要能够分割聚合的输入。
我是Power的新手,所以我可能没有正确地编写语法。我尝试过各种平均迭代,总结,群组等等。
所有的帮助都非常感谢!
下面是我正在处理的数据的一个示例:
Name uniqueID Equipment_Number Failure_Mode Rating A A1 A1A Succcess 1 A A1 A1A Low 2 A A1 A1B Succcess 1 A A1 A1B Success 1 A A2 A2A Succcess 1 A A2 A2A High 4 A A2 A2B High 4 A A2 A2B High 4
B B1 B1A Succcess 1 B B1 B1A Succcess 1 B B1 B1B Succcess 1 B B1 B1B High 4 B B2 B2A Low 2 B B2 B2A Success 1 B B2 B2B Medium 3 B B2 B2B Low 2
我想有三项措施:
Three successive measures:
using the Rating Data from the table above
Equipment_Number Max
A1A 2
A1B 1
A2A 4
A2B 4
B1A 1
B1B 4
B2A 2
B2B 3
using the Equipment_Number max measure grouping by uniqueID
uniqueID Max
A1 2
A2 4
B1 4
B2 3
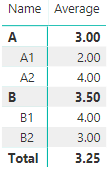
using the uniqueID max measure grouping by Name
Name Average
A 3
B 3.5回答 1
Stack Overflow用户
发布于 2019-07-02 15:51:26
这是因为当您定义变量时,它是一个固定的值。也就是说,__Module_Rating_Measure是固定的。
然后,您的第二个VAR,__System_Rating_Measure给出相同的常数,因为每个最大值都是相同的固定值。平均水平也一样。
尝试将这些VAR部件定义为单独的度量,而不是与变量相同的度量。
另一种选择是使用SUMMARIZE构建表变量,而不是标量变量。
对于更具体的细节,它将有助于编辑您的问题,以提供样本数据和期望的结果。
编辑:,我看不出有什么理由把这个最大值取两次。只需在uniqueID级别取一次最大值,然后平均:
Average =
AVERAGEX (
VALUES ( Table1[uniqueID] ),
CALCULATE (
MAX ( Table1[Rating] ),
Table1[uniqueID] = EARLIER ( Table1[uniqueID] )
)
)这将迭代当前筛选器上下文中的每个uniqueID值,并计算该ID的最大Rating,然后取平均值。
https://stackoverflow.com/questions/56855824
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号