
用于响应的Likert图例名称
用于响应的Likert图例名称
提问于 2019-06-30 12:39:21
我已经开发了一个脚本来绘制一个Likert比例。剧本工作正常,情节正确。我想把回应标签改为:“强烈反对”、“不同意”、“稍不同意”、“稍同意”、“同意”、“强烈同意”。我尝试过不同的解决方案,但似乎没有一种可行。
Q1 <- read_excel("C:\\Users\\users\\Desktop\\Survey Responses\\Business Survey\\BusinessLikert.xlsx")
df <- data.frame(respondent = c(Q1$Respondent), Score = c(Q1$Q1))
df1 <- likert(items=df[,2, drop = FALSE], nlevels = 6)
summary(df1)
likert.bar.plot(df1)
likert.density.plot(df1)
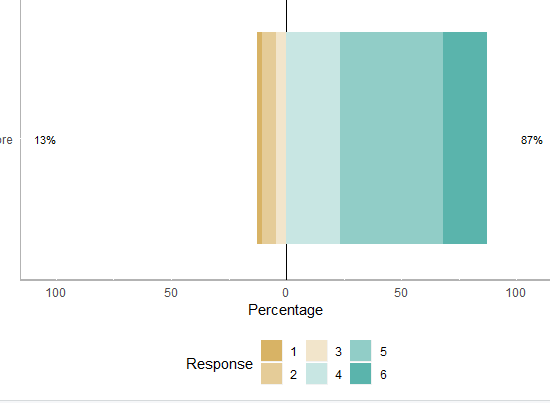
回答 1
Stack Overflow用户
发布于 2019-06-30 19:10:42
正如likert函数(?likert::likert)的文档中所述,items中的data.frame列应该是因素。然后,级别名称指定派生的likert绘图中使用的响应标签。由于您的数据不可复制,请考虑以下人工示例:
library(likert)
set.seed(1)
df <- data.frame(Score = factor(sample(1:6, size = 100, replace = TRUE),
labels = c("Strongly Disagree", "Disagree", "Slightly Disagree", "Slightly Agree", "Agree", "Strongly Agree")))
(df_likert <- likert(items = df))
#> Item Strongly Disagree Disagree Slightly Disagree Slightly Agree Agree
#> 1 Score 19 18 12 15 15
#> Strongly Agree
#> 1 21
likert.bar.plot(df_likert)
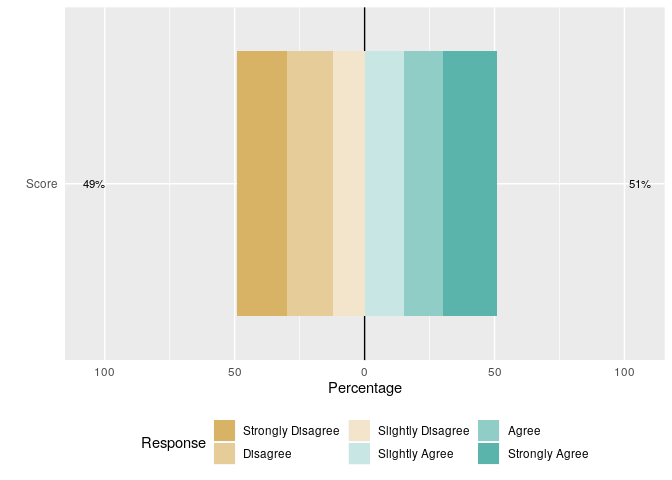
编辑:用于表示data.frame中各个响应组的多个(例如数字)列,首先将这些列作为因子重新编码,然后将likert函数应用于已编码的data.frame:
## initial data.frame of integers
df <- data.frame(
sapply(c("Q1", "Q2", "Q3"), function(x) sample(1:6, size = 100, replace = TRUE))
)
## recode each column as a factor
df_factor <- as.data.frame(
lapply(df, function(x) factor(x,
labels = c("Strongly Disagree", "Disagree", "Slightly Disagree",
"Slightly Agree", "Agree", "Strongly Agree"))
)
)
(df_likert <- likert(items = df_factor))
#> Item Strongly Disagree Disagree Slightly Disagree Slightly Agree Agree
#> 1 Q1 19 18 12 15 15
#> 2 Q2 19 16 19 18 15
#> 3 Q3 18 15 8 21 20
#> Strongly Agree
#> 1 21
#> 2 13
#> 3 18
likert.bar.plot(df_likert)
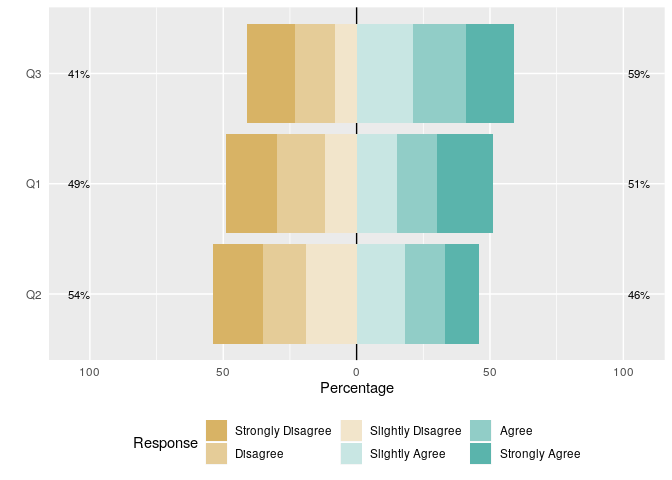
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56824915
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号