
分布式训练是否产生在每个分布节点内训练的平均NNs神经网络?
我目前正在筛选大量关于神经网络分布式训练(反向传播的训练)的材料。我越深入研究这些材料,我就越觉得每一个分布式神经网络训练算法都只是一种结合分布式节点(通常使用平均值)产生的梯度与执行环境的约束(即网络拓扑结构、节点性能相等、.)之间的梯度的一种方法。
所有的底层算法都集中在对执行环境约束的假设的挖掘上,目的是减少总体滞后,从而减少完成训练所需的总时间。
因此,如果我们只是以某种巧妙的方式将梯度和分布式训练结合起来,那么整个过程训练就相当于每个分布式节点内的训练所产生的网络平均。
如果我对上面描述的事情是正确的,那么我想尝试将由分布式节点手工生成的权重组合起来。
,所以我的问题是:,如何使用任何主流技术,例如tensorflow / caffe / mxnet /.
提前谢谢你
编辑@Matias Valdene格罗
Matias,我明白你在说什么:你的意思是,一旦你应用梯度,新梯度就会改变,因此不可能并行化,因为旧梯度与新更新的权重无关。所以现实世界的算法评估梯度,平均它们,然后应用它们。
现在,如果您在这个数学运算中展开括号,那么您会注意到您可以在本地应用渐变。本质上,如果平均三角(向量)或平均NN状态(点),就没有区别。请参阅下图:
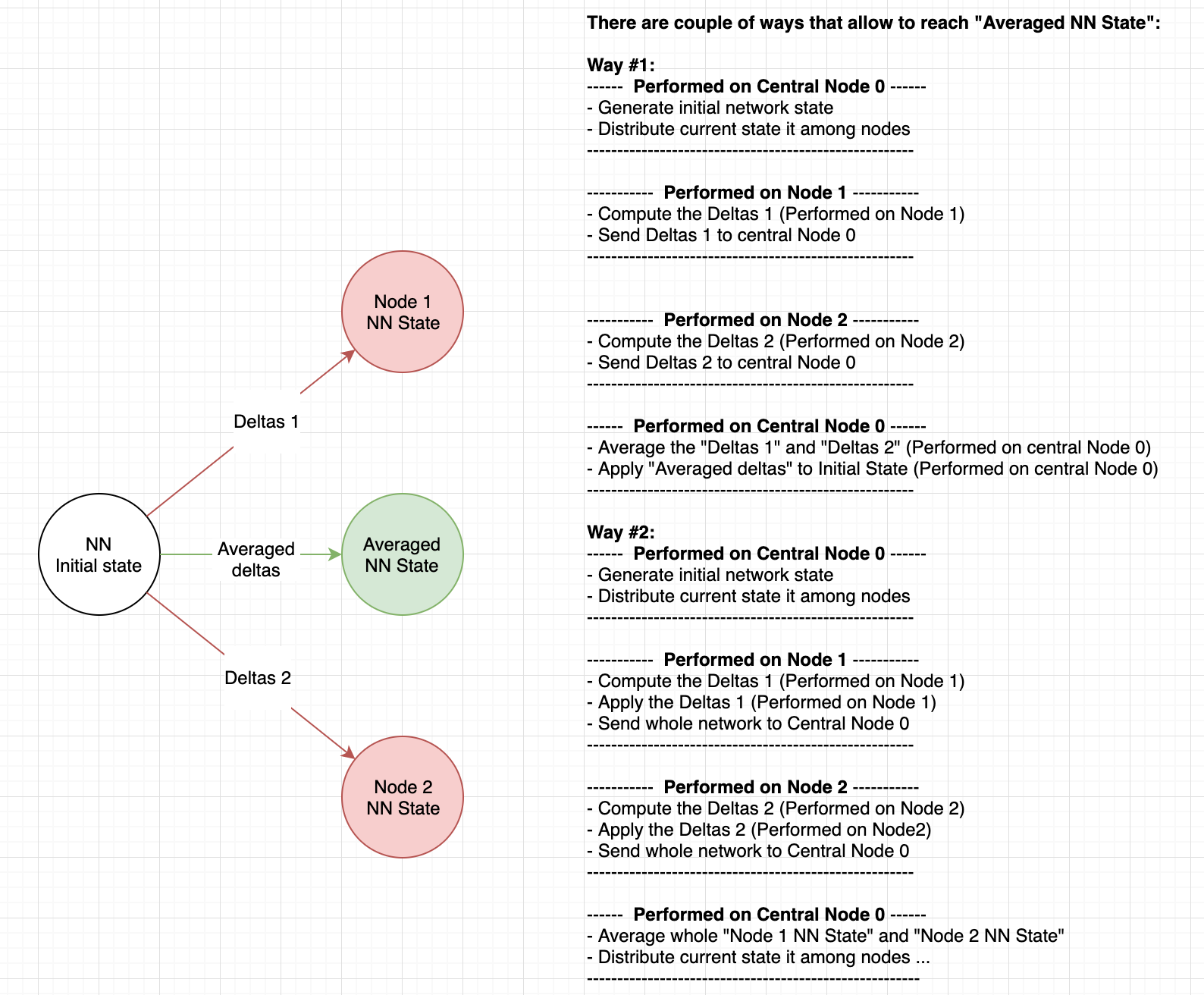
假设NN权值是二维向量.
Initial state = (0, 0)
Deltas 1 = (1, 1)
Deltas 2 = (1,-1)
-----------------------
Average deltas = (1, 1) * 0.5 + (1, -1) * 0.5 = (1, 0)
NN State = (0, 0) - (1, 0) = (-1, 0)现在,如果在节点上局部应用梯度,中心节点将对权重进行平均,而不是增量,则可以获得相同的结果:
--------- Central node 0 ---------
Initial state = (0, 0)
----------------------------------
------------- Node 1 -------------
Deltas 1 = (1, 1)
State 1 = (0, 0) - (1, 1) = (-1, -1)
----------------------------------
------------- Node 2 -------------
Deltas 2 = (1,-1)
State 2 = (0, 0) - (1, -1) = (-1, 1)
----------------------------------
--------- Central node 0 ---------
Average state = ((-1, -1) * 0.5 + (-1, 1) * 0.5) = (-1, 0)
----------------------------------结果是一样的。
回答 1
Stack Overflow用户
发布于 2019-07-02 01:24:16
标题中的问题与正文中的问题不同:)我将回答这两个问题:
题目::“分布式训练是否产生神经网络,即在每个分布式节点内训练的平均神经网络?”。
不是的。在使用小型批量SGD的模型训练中,分布式训练通常是指数据并行分布式培训,它在N个工作人员上分发一小批记录的梯度计算,然后生成一个平均梯度,用于以异步或同步的方式更新中心模型权重。历史上,平均发生在一个名为参数服务器( MXNet和TensorFlow中的历史默认)的单独过程中,但现代方法使用的是一种更节省网络、点对点环式的全缩减,由优步的Horovod扩展民主化,最初是为TensorFlow但现在也可用于Keras、PyTorch和MXNet。开发的。请注意,模型--并行分布式培训(在不同的设备中拥有模型的不同部分)也存在,但数据并行培训在实践中更为常见,这可能是因为实现起来更简单(分发平均值很容易),而且充分的模型通常可以轻松地存储在现代硬件的内存中。但是,对于非常大的模型,例如谷歌GNMT,有时也会看到模型并行培训。
身体问题::“如何使用任何主流技术平均产生两个或更多的神经网络权重?”。
这取决于每个框架API,例如:
在TensorFlow:Tensorflow -恢复模型的平均模型权重中
在PyTorch:如何计算两个网络的平均权重?中
在MXNet (假设初始化的gluon nn.Sequential()模型具有类似体系结构的虚拟代码)中:
# create Parameter dict storing model parameters
p1 = net1.collect_params()
p2 = net2.collect_params()
p3 = net3.collect_params()
for k1, k2, k3 in zip(p1, p2, p3):
p3[k3].set_data(0.5*(p1[k1].data() + p2[k2].data()))https://stackoverflow.com/questions/56824036
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号