
由uniE0A1返回的“FT_Get_Glyph_Name”的含义是什么?
这个问题很可能是我不理解一些基本问题的结果,但我真的可以在一些帮助下做到这一点,如下所示。
当我试图将头绕在文本呈现、自由键入等方面时,我遇到了一些奇怪的符号,当我解开它时,它报告自己与unicode代码点相关联,但是当我从unicode端检查时,这个代码点是无效的。
例如,使用索引1437中的字形"Hack“就是这些神秘字形的一个例子,请参见下面的内容。
下面是使用freetype-py python包装器freetype的一些演示代码。
首先,作为一个看似可信的例子,并且适用于>99%的象形文字,让我们来看看字母"A"
import numpy as np
import freetype as FT
import unicodedata
ff = FT.Face('/usr/share/fonts/truetype/Hack-Regular.ttf')
ff.set_char_size(12<<6)
ff.load_glyph(1425)
ff.get_glyph_name(1425)
# b'uni0041'十六进制41是小数点65,它是'A‘的ascii/unicode,而呈现的位图看起来也是'A’。
np.array(ff.glyph.bitmap.buffer).reshape(-1,8)
# array([[ 0, 0, 67, 255, 121, 0, 0, 0],
# [ 0, 0, 143, 213, 198, 0, 0, 0],
# [ 0, 0, 218, 85, 250, 21, 0, 0],
# [ 0, 38, 248, 9, 203, 95, 0, 0],
# [ 0, 115, 191, 0, 136, 171, 0, 0],
# [ 0, 191, 125, 0, 69, 242, 5, 0],
# [ 15, 250, 252, 252, 252, 255, 68, 0],
# [ 87, 231, 2, 0, 0, 178, 145, 0],
# [162, 152, 0, 0, 0, 97, 221, 0]])
unicodedata.name(chr(0x0041))
# 'LATIN CAPITAL LETTER A'现在,让我们对字形索引1437做同样的操作:
ff.load_glyph(1437)
ff.get_glyph_name(1437)
# b'uniE0A1'
np.array(ff.glyph.bitmap.buffer).reshape(-1,5)
# array([[ 56, 70, 0, 0, 0],
# [112, 140, 0, 0, 0],
# [112, 140, 0, 0, 0],
# [112, 140, 0, 0, 0],
# [112, 140, 0, 0, 0],
# [112, 140, 0, 0, 0],
# [105, 232, 224, 178, 0],
# [ 0, 168, 150, 40, 216],
# [ 0, 168, 241, 46, 216],
# [ 0, 168, 223, 124, 216],
# [ 0, 168, 131, 215, 216],
# [ 0, 168, 81, 212, 216],
# [ 0, 168, 84, 108, 216]])
unicodedata.name(chr(0xE0A1))
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: no such name因此,字形本身称为"uniE0A1“,但正如我所说的,unicode在那里没有代码点(我反复检查,它不在UnicodeData.txt (我想是12版)中),我也不识别位图。
这个问题与字符是松散相关的,这是另一个没有加起来的东西的例子。
回答 2
Stack Overflow用户
发布于 2019-06-22 20:19:25
代码点U+E0A1位于专用区域。字体可以用于自定义字符。
Stack Overflow用户
发布于 2019-06-24 07:22:12
我刚刚安装了hack-fonts-3.003,并检查了代码点U+E0A1生成的字符所产生的字形:
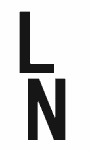
此字符在电力线启用应用程序中用作行号指示符。由于这个角色目前生活在一个私人的使用区域,它的意义与它的外观是分离的。换句话说,只有当你已经知道角色的样子是什么的时候,你才能推断出它的意思。我知道它是什么(因为我熟悉主题),你(OP)不知道。
因此,为了解决这个问题,存在一个建议将电力线字符包含在Unicode本身中。一旦提案被采纳,字体和应用程序就会从无名的、毫无意义的U+E0A1 ‹›切换到U+2FE1 ‹› \N{LINE NUMBER INDICATOR}。
uniE0A1在字体中是一个名称错误的标识符,字体作者懒惰或粗心。它应该被称为line_number_indicator,或者有一个类似的有意义的名称。
https://stackoverflow.com/questions/56718675
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号