
使用dtreeviz可视化决策树
我喜欢Dtreeviz库- GitHub提供的决策树可视化,并且可以使用
# Install libraries
!pip install dtreeviz
!apt-get install graphviz
# Sample code
from sklearn.datasets import *
from sklearn import tree
from dtreeviz.trees import *
from IPython.core.display import display, HTML
classifier = tree.DecisionTreeClassifier(max_depth=4)
cancer = load_breast_cancer()
classifier.fit(cancer.data, cancer.target)
viz = dtreeviz(classifier,
cancer.data,
cancer.target,
target_name='cancer',
feature_names=cancer.feature_names,
class_names=["malignant", "benign"],
fancy=False)
display(HTML(viz.svg()))然而,当我将上面的内容应用到我自己制作的dtree中时,代码就会弹出,因为我的数据是在一个熊猫DF (或np数组)中,而不是一个scikit学习集群对象中。
现在,在Sci-kit学习-如何创建一个集群对象,他们非常严厉地告诉我不要尝试创建一个bunch对象;但我也不具备将我的DF或NP数组转换为上面的viz函数将接受的东西的技能。
我们可以假设我的DF有九个特性和一个目标,名为'Feature01‘、'Feature02’等等和‘target 01’。
这个我通常会分开
FeatDF = FullDF.drop( columns = ["Target01"])
LabelDF = FullDF["Target01"]然后设置我的快乐方式来分配一个分类器,或者如果对于ML,则创建一个测试/训练拆分。
在调用dtreeviz时,所有这些都没有帮助--它期待的是诸如"feature_names“这样的东西(我认为这是包含在"bunch”对象中的东西)。因为我不能把我的DF转换成一堆,所以我被困住了。请拿出你的智慧来。
更新:我想任何简单的DF都会说明我的难题。我们可以一起摇摆
import pandas as pd
Things = {'Feature01': [3,4,5,0],
'Feature02': [4,5,6,0],
'Feature03': [1,2,3,8],
'Target01': ['Red','Blue','Teal','Red']}
DF = pd.DataFrame(Things,
columns= ['Feature01', 'Feature02',
'Feature02', 'Target01']) 作为一个例子,DF。现在,我能走了吗
DataNP = DF.to_numpy()
classifier.fit(DF.data, DF.target)
feature_names = ['Feature01', 'Feature02', 'Feature03']
#..and what if I have 50 features...
viz = dtreeviz(classifier,
DF.data,
DF.target,
target_name='Target01',
feature_names=feature_names,
class_names=["Red", "Blue", "Teal"],
fancy=False) 还是这个蠢蛋?到目前为止,感谢您的指导!
回答 2
Stack Overflow用户
发布于 2019-06-20 12:00:58
- sklearn的决策树需要数值目标值
- 可以使用sklearn的
LabelEncoder将字符串转换为整数 从学习入门导入预处理label_encoder = preprocessing.LabelEncoder() label_encoder.fit(df.Target01) df‘’target‘= label_encoder.transform(df.Target01) dtreeviz期望class_names是一个list或dict,所以让我们从label_encoder获得它 class_names = list(label_encoder.classes_)
完整代码
import pandas as pd
from sklearn import preprocessing, tree
from dtreeviz.trees import dtreeviz
Things = {'Feature01': [3,4,5,0],
'Feature02': [4,5,6,0],
'Feature03': [1,2,3,8],
'Target01': ['Red','Blue','Teal','Red']}
df = pd.DataFrame(Things,
columns= ['Feature01', 'Feature02',
'Feature02', 'Target01'])
label_encoder = preprocessing.LabelEncoder()
label_encoder.fit(df.Target01)
df['target'] = label_encoder.transform(df.Target01)
classifier = tree.DecisionTreeClassifier()
classifier.fit(df.iloc[:,:3], df.target)
dtreeviz(classifier,
df.iloc[:,:3],
df.target,
target_name='toy',
feature_names=df.columns[0:3],
class_names=list(label_encoder.classes_)
)
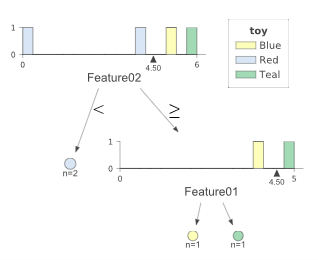
旧答案
让我们使用癌症数据集来创建Pandas数据集
df = pd.DataFrame(cancer.data, columns=cancer.feature_names)
df['target'] = cancer.target这给了我们下面的数据。
mean radius mean texture mean perimeter mean area mean smoothness mean compactness mean concavity mean concave points mean symmetry mean fractal dimension radius error texture error perimeter error area error smoothness error compactness error concavity error concave points error symmetry error fractal dimension error worst radius worst texture worst perimeter worst area worst smoothness worst compactness worst concavity worst concave points worst symmetry worst fractal dimension target
0 17.99 10.38 122.8 1001.0 0.1184 0.2776 0.3001 0.1471 0.2419 0.07871 1.095 0.9053 8.589 153.4 0.006399 0.04904 0.05373 0.01587 0.03003 0.006193 25.38 17.33 184.6 2019.0 0.1622 0.6656 0.7119 0.2654 0.4601 0.1189 0
1 20.57 17.77 132.9 1326.0 0.08474 0.07864 0.0869 0.07017 0.1812 0.05667 0.5435 0.7339 3.398 74.08 0.005225 0.01308 0.0186 0.0134 0.01389 0.003532 24.99 23.41 158.8 1956.0 0.1238 0.1866 0.2416 0.186 0.275 0.08902 0
2 19.69 21.25 130.0 1203.0 0.1096 0.1599 0.1974 0.1279 0.2069 0.05999 0.7456 0.7869 4.585 94.03 0.00615 0.04006 0.03832 0.02058 0.0225 0.004571 23.57 25.53 152.5 1709.0 0.1444 0.4245 0.4504 0.243 0.3613 0.08758 0
[...]
568 7.76 24.54 47.92 181.0 0.05263 0.04362 0.0 0.0 0.1587 0.05884 0.3857 1.428 2.548 19.15 0.007189 0.00466 0.0 0.0 0.02676 0.002783 9.456 30.37 59.16 268.6 0.08996 0.06444 0.0 0.0 0.2871 0.07039 1对于你的分类器,它可以按以下方式使用。
classifier.fit(df.iloc[:,:-1], df.target)也就是说,只需将除最后一列以外的所有列作为训练/输入,而将target列作为输出/目标。
可视化也是如此:
viz = dtreeviz(classifier,
df.iloc[:,:-1],
df.target,
target_name='cancer',
feature_names=df.columns[0:-1],
class_names=["malignant", "benign"]) Stack Overflow用户
发布于 2019-06-20 11:19:39
我认为您与文档中提供的示例混淆了。
这里让我们看一下虹膜数据集的示例。
from sklearn.datasets import *
# Loading iris data
iris = load_iris()
# Type of iris
type(iris)
<class 'sklearn.utils.Bunch'>正如您所提到的,数据集存储为一个sklearn集群对象。
但是dtreeviz没有在它的任何参数中使用这个对象。所有参数都是numpy数组。
# Iris data - parameter
type(iris.data)
<class 'numpy.ndarray'>
# Shape
data.data.shape
(150, 4)因此,很明显,dtreeviz方法使用的是numpy数组,并且没有使用Bunch对象。在您的示例中,功能名称与所选功能的列名无关。
更新
# Replace the following the the sample code to fit your dataframe
cancer.data <> DF.iloc[:, :-1]
cancer.target <> DF['Target01']
# Other parameters
feature_names = DF.columns[:-1]
class_names = DF['Target01'].unique()https://stackoverflow.com/questions/56683489
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号