
获取特定区域的字符串
获取特定区域的字符串
提问于 2019-06-15 02:27:36
我需要使用powershell代码来获取特定区域的字符串。
请看下面的图片,绿色矩形的内容需要保留,所有其他字符串都被删除。
我在第二个区域添加了一些子字符串。它们看起来更复杂。我想知道我是否可以一次提取想要的数据。
需要获取数据:
- abc不好
c高速缓存/L1-缓存
内存阵列/系统存储器
-太好
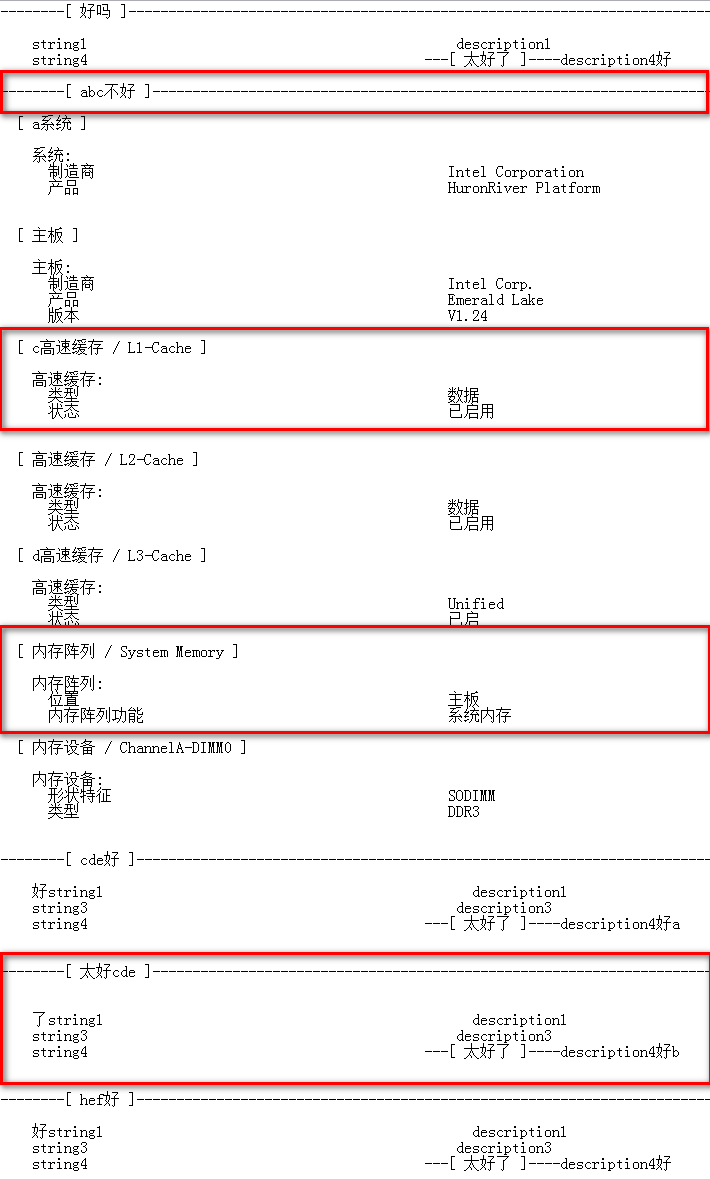
--------[ 好吗 ]----------------------------------------------------------------------------------------------
string1 description1
string4 ---[ 太好了 ]----description4好
--------[ abc不好 ]----------------------------------------------------------------------------------------------------
[ a系统 ]
系统:
制造商 Intel Corporation
产品 HuronRiver Platform
[ 主板 ]
主板:
制造商 Intel Corp.
产品 Emerald Lake
版本 V1.24
[ c高速缓存 / L1-Cache ]
高速缓存:
类型 数据
状态 已启用
[ 高速缓存 / L2-Cache ]
高速缓存:
类型 数据
状态 已启用
[ d高速缓存 / L3-Cache ]
高速缓存:
类型 Unified
状态 已启
[ 内存阵列 / System Memory ]
内存阵列:
位置 主板
内存阵列功能 系统内存
[ 内存设备 / ChannelA-DIMM0 ]
内存设备:
形状特征 SODIMM
类型 DDR3
--------[ cde好 ]---------------------------------------------------------------------------------------------------------
好string1 description1
string3 description3
string4 ---[ 太好了 ]----description4好a
--------[ 太好cde ]----------------------------------------------------------------------------------------------------
了string1 description1
string3 description3
string4 ---[ 太好了 ]----description4好b
--------[ hef好 ]----------------------------------------------------------------------------------------------------
好string1 description1
string3 description3
string4 ---[ 太好了 ]----description4好回答 2
Stack Overflow用户
回答已采纳
发布于 2019-06-15 11:34:06
假设输入来自一个文件,我
Get-Content file.txt -raw和- 用前瞻将标尺行的开始部分分割成若干段
- 使用
Where-Object在该节中使用唯一的单词进行筛选
$Unique = [regex]::Escape("[ abc")
(Get-Content .\file.txt -raw) -split '(?M)(?=^--------\[)' -ne '' |
Where-Object { $PSItem -match $Unique}样本输出:
--------[ abc不好 ]----------------------------------------------------------------------------------------------------
好string1 description1
string2 description2
好string3 description3
string4 ---[ 太好了 ]----description4好2编辑:修改后的需求脚本
$Unique = 'abc不好|太好cde|c高速缓存 \/ L1-Cache|内存阵列 \/ System Memory'
(Get-Content .\SU_56606905.txt -raw) -split '(?M)(?=(^--------\[|^ \[))'|
Where-Object { $PSItem -match $Unique}样本输出:
--------[ abc不好 ]----------------------------------------------------------------------------------------------------
[ c高速缓存 / L1-Cache ]
高速缓存:
类型 数据
状态 已启用
[ 内存阵列 / System Memory ]
内存阵列:
位置 主板
内存阵列功能 系统内存
--------[ 太好cde ]----------------------------------------------------------------------------------------------------
了string1 description1
string3 description3
string4 ---[ 太好了 ]----description4好bStack Overflow用户
发布于 2019-06-15 02:35:00
我们可以从收集新行的表达式开始:
.*(\[ ddf \]|\[ edf \])[\s\S]*?description4\s*.*(\[ ddf \]|\[ edf \])[\s\S]*?\s*(?<=--------\[).*(\[ ddf \]|\[ edf \])[\s\S]*?\s*\n(?:-)如果描述4中有一个固定的子字符串,我们可以简单地使用它,例如:
.*(\[ ddf \]|\[ edf \])[\s\S]*?---\[ \?\?\?\? \]----.+\s*.*(\[ .*abc.* \]|\[ .*cde \])[\s\S]*?\]----.+\s*编辑:
由于我们有动态模式,并且它将根据我们的输入进行更改,所以我们只需要为每个输入使用一个规则,方法是从左上角获取一个非重复的唯一子字符串,从右下角获取一个不重复的唯一子字符串,然后设计表达式,然后使用逻辑OR连接它们:
(.*(\[ .*系统概述.* \][\s\S]*?LapTop\s*)|(.*\[ AIDA64 Extreme \][\s\S]*?10:14\s*)|(.*\[ DMI \])[\s\S]*?HuronRiver CRB.+\s*)(.*(\[ .*TOP LEFT.* \][\s\S]*?Bottom RIGHT.*\s*))|(.*(\[ .*TOP LEFT.* \][\s\S]*?Bottom RIGHT.*\s*))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56606905
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号