
调用TabPy SCRIPT_REAL时出现“所有字段必须是聚合或常量”的表错误
我通过Tableau工作表中的计算字段调用TabPy服务器来运行假设检验:预订率是否因组而有显著差异?
我有一张桌子,如:
Group Bookings
0 A 1
1 A 0
3998 B 1
3999 B 0在Python中,在同一个服务器(使用python2.7码头映像)上,我想要的测试只是:
from scipy.stats import fisher_exact
df_cont_tbl = pd.crosstab(df['Group'], df['Bookings'])
prop_test = fisher_exact(df_cont_tbl)
print 'Fisher exact test: Odds ratio = {:.2f}, p-value = {:.3f}'.format(*prop_test)返回:Fisher exact test: Odds ratio = 1.21, p-value = 0.102
我将Tableau连接到TabPy服务器,并可以执行hello-world计算字段。例如,我用计算字段返回42:SCRIPT_REAL("return 42", ATTR([Group]),ATTR([Bookings]) )
但是,我尝试使用计算出的字段调用上面的stats函数来提取p值:
SCRIPT_REAL("
import pandas as pd
from scipy.stats import fisher_exact
df_cont_tbl = pd.crosstab(_arg1, _arg2)
prop_test = fisher_exact(df_cont_tbl)
return prop_test[1]
", [Group], [Bookings] )我收到通知:当使用表计算函数或来自多个数据源的字段时,计算包含错误和下拉-所有字段必须是聚合或常量。
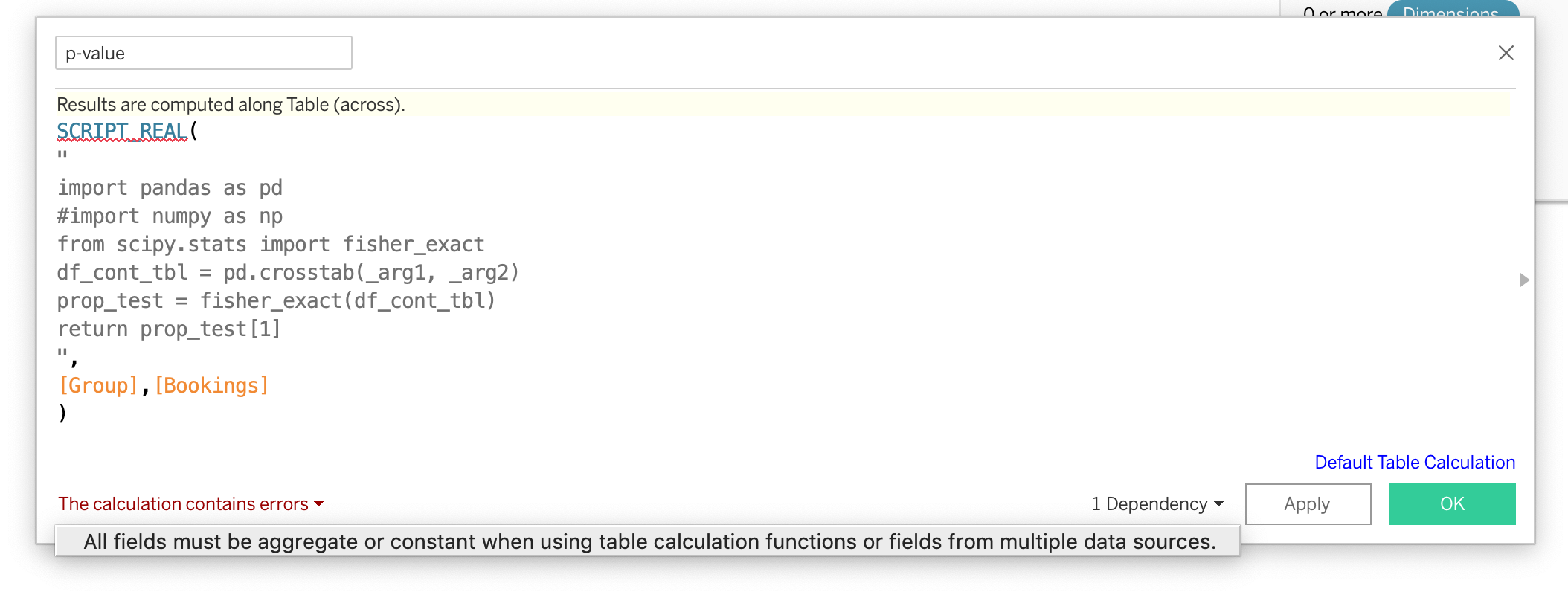
我尝试用ATTR()包装输入,如下所示:
SCRIPT_REAL("
import pandas as pd
from scipy.stats import fisher_exact
df_cont_tbl = pd.crosstab(_arg1, _arg2)
prop_test = fisher_exact(df_cont_tbl)
return prop_test[1]
",ATTR([Group]), ATTR([Bookings])
)将通知更改为“计算是有效的”,但从服务器返回Pandas ValueError:
An error occurred while communicating with the External Service.
Error processing script
Error when POST /evaluate: Traceback
Traceback (most recent call last):
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/tabpy_server/tabpy.py", line 467, in post
result = yield self.call_subprocess(function_to_evaluate, arguments)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/tornado/gen.py", line 1008, in run
value = future.result()
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/tornado/concurrent.py", line 232, in result
raise_exc_info(self._exc_info)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/tornado/gen.py", line 1014, in run
yielded = self.gen.throw(*exc_info)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/tabpy_server/tabpy.py", line 488, in call_subprocess
ret = yield future
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/tornado/gen.py", line 1008, in run
value = future.result()
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/concurrent/futures/_base.py", line 400, in result
return self.__get_result()
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/concurrent/futures/_base.py", line 359, in __get_result
reraise(self._exception, self._traceback)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/concurrent/futures/_compat.py", line 107, in reraise
exec('raise exc_type, exc_value, traceback', {}, locals_)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/concurrent/futures/thread.py", line 61, in run
result = self.fn(*self.args, **self.kwargs)
File "<string>", line 5, in _user_script
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/pandas/tools/pivot.py", line 479, in crosstab
df = DataFrame(data)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/pandas/core/frame.py", line 266, in __init__
mgr = self._init_dict(data, index, columns, dtype=dtype)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/pandas/core/frame.py", line 402, in _init_dict
return _arrays_to_mgr(arrays, data_names, index, columns, dtype=dtype)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/pandas/core/frame.py", line 5398, in _arrays_to_mgr
index = extract_index(arrays)
File "/opt/conda/envs/Tableau-Python-Server/lib/python2.7/site-packages/pandas/core/frame.py", line 5437, in extract_index
raise ValueError('If using all scalar values, you must pass'
ValueError: If using all scalar values, you must pass an index
Error type : ValueError
Error message : If using all scalar values, you must pass an index示例数据集:
要生成我连接到的CSV:
import os
import pandas as pd
import numpy as np
from collections import namedtuple
OUTPUT_LOC = os.path.expanduser('~/TabPy_demo/ab_test_demo_results.csv')
GroupObs = namedtuple('GroupObs', ['name','n','p'])
obs = [GroupObs('A',3000,.10),GroupObs('B',1000,.13)]
# note true odds ratio = (13/87)/(10/90) = 1.345
np.random.seed(2019)
df = pd.concat( [ pd.DataFrame({'Group': grp.name,
'Bookings': pd.Series(np.random.binomial(n=1,
p=grp.p, size=grp.n))
}) for grp in obs
],ignore_index=True )
df.to_csv(OUTPUT_LOC,index=False)回答 1
Stack Overflow用户
发布于 2019-08-23 16:47:26
老问题,但也许这会对其他人有所帮助。有几个问题。首先是数据传递到pd.crosstab的方式。Tableau将一个值列表传递给tabpy服务器,因此将其包装在一个数组中,以修复您正在获取的错误。
SCRIPT_REAL(
"
import pandas as pd
import numpy as np
from scipy.stats import fisher_exact
df_cont_tbl = pd.crosstab(np.array(_arg1), np.array(_arg2))
prop_test = fisher_exact(df_cont_tbl)
return prop_test[1]
",
attr([Group]), attr([Bookings])
)另一个问题是表计算的执行方式。您希望发送两个信息列表,每个列表与您的表一样长。在默认情况下,tableau希望在行级别进行计算,这是不起作用的。
我将行计数F1包含在我构建工作簿的csv中,并确保沿此函数计算python值。
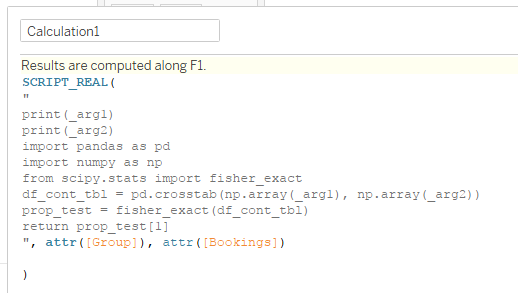
现在,当您将F1放入工作表时,它将尽可能多地返回P值,这是将您的计算封装在另一个计算中,只有当它是第一行时才返回值,并将其放在工作表中。
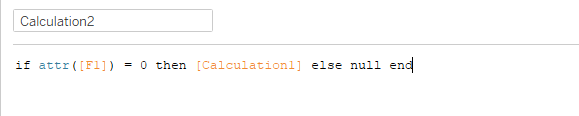
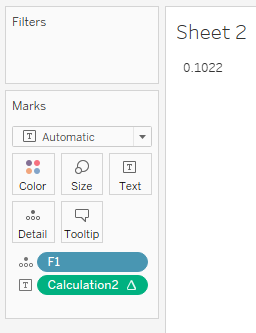
现在您可以将其放入工作表中。
https://stackoverflow.com/questions/56400669
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号