
如何“排序csv文件”python
如何“排序csv文件”python
提问于 2019-05-29 16:32:31
我正在尝试创建一个新的文件,其中只包含级别在9以上的电影的数据。
我正在分析的数据集包含从IMDB获得的许多电影的评级。数据字段是:
Votes:给电影打分的人数Rank:这部电影的平均评级Title:电影的名字Year:电影上映的那一年
我试过的密码:
import csv
filename = "IMDB.txt"
with open(filename, 'rt', encoding='utf-8-sig') as imdb_file:
imdb_reader = csv.DictReader(imdb_file, delimiter = '\t')
with open('new file.csv', 'w', newline='') as high_rank:
fieldnames = ['Votes', 'Rank', 'Title', 'Year']
writer = csv.DictWriter(high_rank, fieldnames=fieldnames)
writer.writeheader()
for line_number, current_row in enumerate (imdb_reader):
if(float(current_row['Rank']) > 9.0):
csv_writer.writerow(dict(current_row))但不幸的是,这不起作用,我该怎么办?
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-05-29 18:12:40
基于你的评论,您的地区默认编码似乎不支持整个Unicode范围。您需要为将处理任意Unicode字符的输出文件指定编码。通常,在非Windows系统上,您将使用'utf-8';在Windows上,您可能使用'utf-16'或'utf-8-sig' (Windows程序通常假设UTF-8在区域编码中没有显式签名,并对其进行错误解释)。修复方法很简单,就像更改一样:
with open('new file.csv', 'w', newline='') as high_rank:至:
with open('new file.csv', 'w', encoding='utf-8', newline='') as high_rank:将指定的encoding更改为对操作系统和用例有意义的任何东西。
Stack Overflow用户
发布于 2019-05-29 17:31:22
让我们考虑一下,您有以下excel工作表名temp.csv,并且希望过滤级别在9以上的电影(包括在内):
一个简单的方法是使用pandas模块。它使你有机会:
假设您有以下数据:
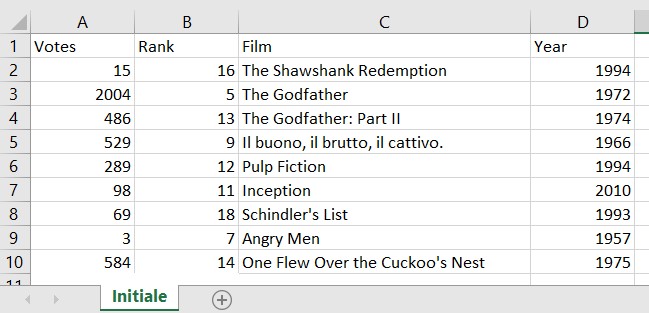
下面的代码完成了这项工作:
# import modules
import pandas as pd
# Path - name of your file
filename = "temp.csv"
# Read the csv file
df = pd.read_csv(filename, sep=";")
print(df)
# Votes Rank Film Year
# 0 15 16 The Shawshank Redemption 1994
# 1 2004 5 The Godfather 1972
# 2 486 13 The Godfather: Part II 1974
# 3 529 9 Il buono, il brutto, il cattivo. 1966
# 4 289 12 Pulp Fiction 1994
# 5 98 11 Inception 2010
# 6 69 18 Schindler's List 1993
# 7 3 7 Angry Men 1957
# 8 584 14 One Flew Over the Cuckoo's Nest 1975
# Filter the csv file
df_filtered = df[df["Rank"] >= 9]
print(df_filtered)
# Votes Rank Film Year
# 0 15 16 The Shawshank Redemption 1994
# 2 486 13 The Godfather: Part II 1974
# 3 529 9 Il buono, il brutto, il cattivo. 1966
# 4 289 12 Pulp Fiction 1994
# 5 98 11 Inception 2010
# 6 69 18 Schindler's List 1993
# 8 584 14 One Flew Over the Cuckoo's Nest 1975
# name new csv file
new_filename = filename[:-3] + "_new" + filename[-3:]
# Export dataframe to csv file
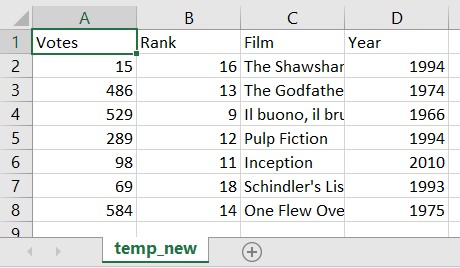
df_filtered.to_csv(new_filename)新的.csv如下所示:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56365001
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号