
线性回归-实现特征缩放
线性回归-实现特征缩放
提问于 2019-05-29 15:38:25
我试图在一个与GRE分数与入学概率有关的数据集上,在Octave 5.1.0中实现线性回归。数据集属于这一类,
337 0.92 324 0.76 316 0.72 322 0.8 。 。 。
我的主程序.m文件看起来,
% read the data
data = load('Admission_Predict.txt');
% initiate variables
x = data(:,1);
y = data(:,2);
m = length(y);
theta = zeros(2,1);
alpha = 0.01;
iters = 1500;
J_hist = zeros(iters,1);
% plot data
subplot(1,2,1);
plot(x,y,'rx','MarkerSize', 10);
title('training data');
% compute cost function
x = [ones(m,1), (data(:,1) ./ 300)]; % feature scaling
J = computeCost(x,y,theta);
% run gradient descent
[theta, J_hist] = gradientDescent(x,y,theta,alpha,iters);
hold on;
subplot(1,2,1);
plot((x(:,2) .* 300), (x*theta),'-');
xlabel('GRE score');
ylabel('Probability');
hold off;
subplot (1,2,2);
plot(1:iters, J_hist, '-b');
xlabel('no: of iteration');
ylabel('Cost function');M看起来,
function J = computeCost(x,y,theta)
m = length(y);
h = x * theta;
J = (1/(2*m))*sum((h-y) .^ 2);
endfunction还有梯度下降。我看起来,
function [theta, J_hist] = gradientDescent(x,y,theta,alpha,iters)
m = length(y);
J_hist = zeros(iters,1);
for i=1:iters
diff = (x*theta - y);
theta = theta - (alpha * (1/(m))) * (x' * diff);
J_hist(i) = computeCost(x,y,theta);
endfor
endfunction图上的图是这样的,
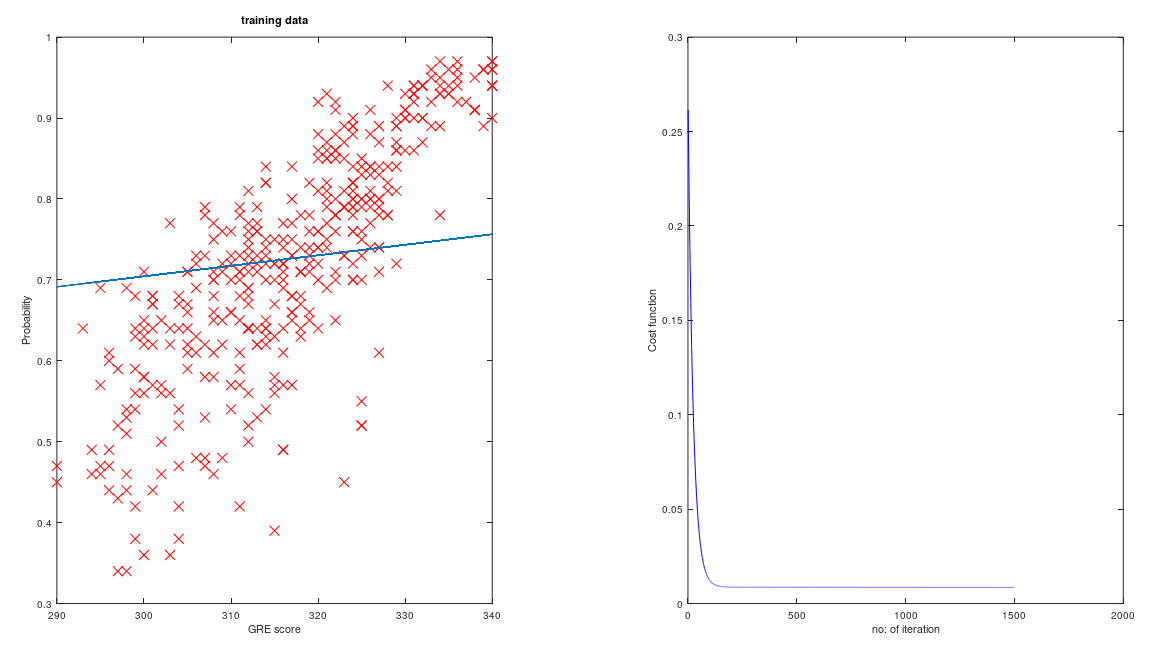
你可以看到,即使我的成本函数似乎被最小化了,也感觉不太对劲。
有人能告诉我这是对的吗?如果没有,我做错了什么?
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-05-29 16:53:46
检查您的实现是否正确的最简单方法是与已验证的线性回归实现进行比较。我建议使用类似于建议的这里的替代实现方法,然后比较结果。如果fits匹配,那么这是对数据的最佳线性拟合,如果它们不匹配,那么您的实现中可能会出现一些错误。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56364169
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号