
处理matplotlib条形图中的倾斜数据
处理matplotlib条形图中的倾斜数据
提问于 2019-05-28 12:27:07
我正在使用为倾斜的数据集创建一个条形图。虽然我可以在没有任何问题的情况下生成图形,但在生成的图表中,与倾斜数据相关的条形图覆盖了大部分条形图,使得其他非倾斜数据看起来相对较小且可以忽略不计。
下面是用来生成条形图的代码。
import numpy as np
import matplotlib.pyplot as plt
x=["A","B","C","D","E","F"]
y=[25,11,46,895,68,5]
fig,ax = plt.subplots()
r1=plt.barh(y=x,
width=y,
height=0.8)
#ht = [x.get_width() for x in r1.get_children()]
r1y = np.asarray([x.get_y() for x in r1.get_children()])
r1h = np.asarray([x.get_height() for x in r1.get_children()])
for i in range(5):
plt.text(y[i],r1y[i]+r1h[i]/2, '%s'% (y[i]), ha='left', va='center')
plt.xticks([0,10,100,1000])
plt.show()
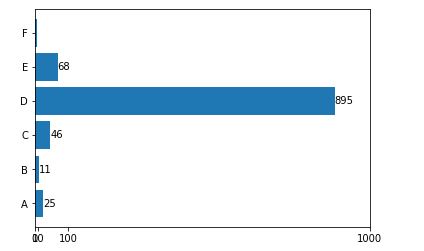
上面的代码将创建一个条形图,以0、10、100和1000作为xtick值,并根据它们的值将它们放置在一个相对距离上。
虽然这是有效的和预期的behvaior,一个单一的倾斜条是影响整个条形图。
那么,是否有可能将这些xtick值放置在等距的位置,从而使倾斜的数据不会占用最终输出中的大部分空间?
在预期产出中,相关的0-10-100应占空间的66.6%左右,而100-1000应占33.3%的空间的其余部分。
示例:

回答 1
Stack Overflow用户
回答已采纳
发布于 2019-05-28 13:15:03
尝试添加plt.xscale('log')
x=["A","B","C","D","E","F"]
y=[25,11,46,895,68,5]
fig,ax = plt.subplots()
r1=plt.barh(y=x,
width=y,
height=0.8)
r1y = np.asarray([x.get_y() for x in r1.get_children()])
r1h = np.asarray([x.get_height() for x in r1.get_children()])
for i in range(5):
plt.text(y[i],r1y[i]+r1h[i]/2, '%s'% (y[i]), ha='left', va='center')
plt.xscale('log')
plt.show()输出:
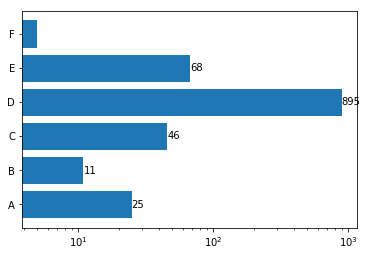
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56342273
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号