
如何使用Python将格式化的“epi-week”转换为日期?
目前,我正努力学习如何将数据科学技能应用到一些个人项目中,这些技能是我通过Coursera和Dataquest学到的。
我从美国卫生和公共服务部()的谷歌BigQuery上找到了一个数据集,其中包括1888年至2013年间公布的所有美国城市和州的每周应呈报疾病监测报告。
我将数据导出到一个.csv文件,并将其导入到我正在通过Anaconda运行的木星笔记本中。在查看数据集的标题时,我注意到日期/周显示为'epi_week‘。
我试图使这些数据更易读,更便于分析,为了做到这一点,我希望把它转换成DD/MM/YYYY或周/月/年等。
我做了一些研究,显然epi周也被称为CDC周,到目前为止,我发现了python 3的扩展/包,它被称为“表周”。
使用这一包,我可以将一些“正常”日期转换为包创建者所指的内容,形成某种epi周形式,但它们与我在dataset中看到的完全不一样。
例如,如果我使用今天的日期,即2019年5月24日(24/05/ 2019 ),则输出是:“2019年的第21周”,但这是数据中的前四项输入(并遵循相同的格式,所有其他输入)是这样的:
epi_week
“197006年”
'197007‘
“197008”
197012年
In [1]: disease_header
Out [1]:
[['epi_week', 'state', 'loc', 'loc_type', 'disease', 'cases', 'incidence_per_100000']]
In [2]: disease[:4]
Out [2]:
[['197006', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0'],
['197007', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0'],
['197008', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0'],
['197012', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0']]回答 1
Stack Overflow用户
发布于 2019-06-27 20:28:56
开发表周包是为了解决像这里这样的问题。
使用您提供的示例数据,让我们创建一个包含周结束日期的新列:
import pandas as pd
from epiweeks import Week
columns = ['epi_week', 'state', 'loc', 'loc_type',
'disease', 'cases', 'incidence_per_100000']
data = [
['197006', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0'],
['197007', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0'],
['197008', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0'],
['197012', 'AK', 'ALASKA', 'STATE', 'MUMPS', '0', '0']
]
df = pd.DataFrame(data, columns=columns)
# Now create a new column with week ending date in ISO format
df['week_ending'] = df['epi_week'].apply(lambda x: Week.fromstring(x).enddate())这样做的结果如下:
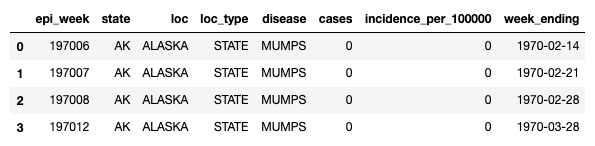
为了获得更多的示例,我建议您查看一下文档包。
如果您只需要使用年份和周列,则不需要使用need包就可以做到这一点:
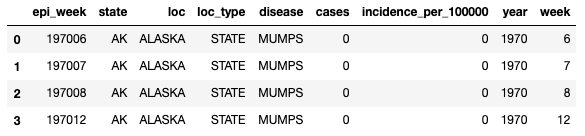
df['year'] = df['epi_week'].apply(lambda x: int(x[:4]))
df['week'] = df['epi_week'].apply(lambda x: int(x[4:6]))这样做的结果如下:
https://stackoverflow.com/questions/56295053
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号