
从发票中提取pdf或图像格式的数据
我正在开发发票解析器,它从pdf中的发票中提取数据,或者图像format.It用非表格数据处理简单的pdf,但是给出了大量的输出数据,用包含表格的pdf处理。我无法找到一个通用的解决方案。
Invoice2Data:它基于templates.It,在json格式下给出了相当好的结果,直到包含动态表的复杂pdfs的now.But模板创建才变得复杂。
Tabula:表提取基于表的坐标为extracted.If,表中的数据增加了表的长度,因此坐标changes.So在这种情况下给出了错误的结果。
Pdftotext:它将任何pdfs转换为文本,但格式需要大量解析,而我们不想要这种格式。
Aws_Textract和Elis_Rossum_Ai:给出json format.But中的所有数据,如果表列包含多行,那么json解析就变成difficult.Even,json给出的解析规模很大。
Tesseract:与pdftotext.Complex相同,pdfs是不可解析的。
除了所有这些或以上库的组合,任何人都能解析复杂的pdf数据,请帮助。
回答 1
Stack Overflow用户
发布于 2020-08-13 17:59:56
我正在处理一个类似的商业问题。由于发票没有固定的格式,所以不能直接使用任何文本解析方法。
要解决这个问题,必须使用计算机视觉(深度学习)进行现场检测,使用Pytesseract OCR将图像转换为文本。为了更好地理解以下步骤:
- 将发票转换成图像,并使用像labelImg这样的工具用地址、数量等字段对图像进行注释。(为了取得更好的效果,请使用不同类型的500-1000张发票)
- 生成XML文件后,训练任何对象检测模型,如YOLO或TF对象检测API。
- 该模型将检测字段并给出感兴趣区域(ROI)的坐标。喜欢
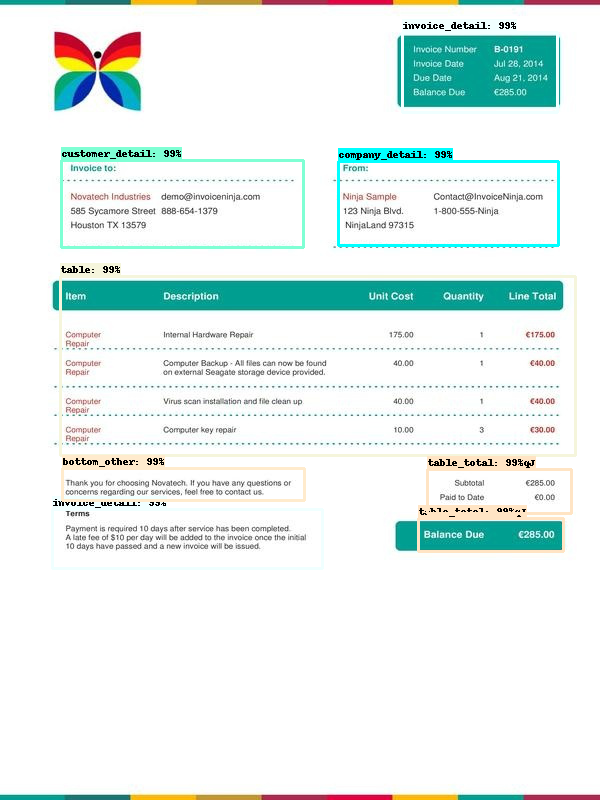
- 在ROI坐标上应用Pytessract OCR。Click Here
- 最后,使用regex验证提取字段中的文本,并执行任何必要的操作/转换。最后将数据存储到CSV或数据库。
希望我的回答对你有帮助!向上投票的答案,使它达到最大的人。
https://stackoverflow.com/questions/56278094
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号