
如何删除一行,因为它在另一列中只有一个或相同的项?
如何删除一行,因为它在另一列中只有一个或相同的项?
提问于 2019-05-15 18:04:21
我准备了一个小例子:exp.pic
{kind=link}
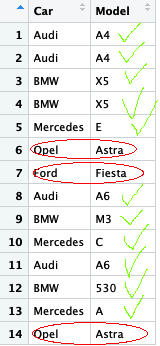
我想删除欧宝的线条,因为欧宝两次出现,同样的model.And,福特只出现一次。
我只想要有至少两种不同型号的车。
Car<-c("Audi","Audi","BMW","BMW","Mercedes","Opel","Ford","Audi","BMW","Mercedes","Audi","BMW","Mercedes","Opel")
Model<-c("A4","A4","X5","X5","E","Astra","Fiesta","A6","M3","C","A6","530","A","Astra")
Car<-cbind(Car,Model)
Car<-data.frame(Car)输出应该如下所示:

例如,只要有另一款奥迪,奥迪A4就会出现五倍。
我希望我能解释清楚。
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-05-15 18:57:47
dplyr的又一次尝试
Car %>%
group_by(Car) %>%
filter(n_distinct(Model) > 1) %>%
ungroup() %>%
arrange(Car, Model)
# # A tibble: 11 x 2
# Car Model
# <fct> <fct>
# 1 Audi A4
# 2 Audi A4
# 3 Audi A6
# 4 Audi A6
# 5 BMW 530
# 6 BMW M3
# 7 BMW X5
# 8 BMW X5
# 9 Mercedes A
# 10 Mercedes C
# 11 Mercedes E Stack Overflow用户
发布于 2019-05-15 19:04:13
使用subset,我们可以过滤多个独特的车型的汽车公司。
out <- subset(Cars, ave(Model, Car, FUN = function(x) length(unique(x))) > 1)
out
# Car Model
#1 Audi A4
#2 Audi A4
#3 BMW X5
#4 BMW X5
#5 Mercedes E
#8 Audi A6
#9 BMW M3
#10 Mercedes C
#11 Audi A6
#12 BMW 530
#13 Mercedes A数据
Cars <- data.frame(Car, Model, stringsAsFactors = FALSE)
# ^ note the different name页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56155248
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号