
当在数据库上使用df.bulkCopyToSqlDB时,sql从未完成过1000万条记录
当在数据库上使用df.bulkCopyToSqlDB时,sql从未完成过1000万条记录
提问于 2019-05-14 08:25:38
我正在读取1GB的CSV文件(记录计数:1000万,列: 13 ),并试图将其转储到SQL服务器中。以下是详细资料:
- CSV文件位置: azure blob存储
- 代码:星星之火+ Scala
- 群集:数据库大小:
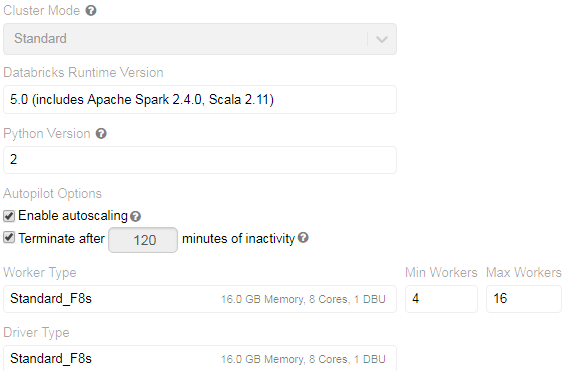
- 用于读取文件并将其转储的代码: ( val = spark.read.format(fileparser_config("fileFormat").asString).option("header",fileparser_config("IsFirstRowHeader").toString).load(fileparser_config("FileName").asString).withColumn("_ID",monotonically_increasing_id) val bulkCopyConfig = Config(Map( "url“-> connConfig("dataSource").asString,"databaseName”-> connConfig("dbName").asString,"user“-> connConfig("userName").asString,"password”-> connConfig("password").asString,"dbTable“->,”en22 20#“500000,"true",( "bulkCopyTimeout“->”600“) println(s“${LocalDateTime.now()} * df.bulkCopyToSqlDB(bulkCopyConfig) println(s“${LocalDateTime.now()} *
- 问题:
集群陷入了困境,我的工作从未完成。有一次,当它运行足够长的时间时,它抛出了一个错误:
org.apache.spark.SparkException: Job aborted due to stage failure: Task 13 in stage 38.0 failed 4 times, most recent failure: Lost task 13.3 in stage 38.0 (TID 1532, 10.0.6.6, executor 4): com.microsoft.sqlserver.jdbc.SQLServerException: The connection is closed.\n\tat com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDriverError(SQLServerException.java:227)\n\tat com.microsoft.sqlserver.jdbc.SQLServerConnection.checkClosed(SQLServerConnection.java:796)\n\tat com.microsoft.sqlserver.jdbc.SQLServ- 集群事件日志:

- 其他意见:
1. While the job runs for a very long time, the cluster is not completely unresponsive. I tried this by submitting more jobs in that same window. The job ran but took comparatively more time than usual( around 10x time)
2. I tried increasing the worker nodes and the node type ( even chose 128 GB nodes ) but still the outcome was same.
3. While the job was running, I tried checking the SQL table row count with nolock query. I ran this after 3-4 minutes while the job was running, it gave me around 2 million records in the table. But when I ran it again after 10 minutes, the query kept running forever and never returned any records.
4. I have tried tweaking the bulkCopyBatchSize property but it hasnt helped much.
5. I have tried to remove the sqlinsertion code and used an aggregation operation on the dataframe that i create from 1 GB file and the entire thing takes only 40-50 seconds, so the problem is only with sql driver/sql server.
回答 1
Stack Overflow用户
发布于 2019-09-12 06:27:10
我也面临着同样的问题。
Azure Server -标准S7: 800个DTU
HDInsight -6节点(2个D13V2头和4个D13V2工作人员)
数据大小为-100 1.7的Parquet有17亿行。
最初,我使用"bulkCopyTimeout"作为600秒,并观察到加载是在超时之后重新启动的。然后,我将超时值更改为一个非常大的值,它运行得很好。
为提高业绩:
在目标表中创建列存储索引并使用
"bulkCopyBatchSize" = 1048576 (将整个批处理加载到行组最大容量,并将它们直接压缩到列存储中,而不是加载到增量存储中,然后再进行压缩)。
"bulkCopyTableLock" = "false“(为了允许并行)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56126012
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号