
数据科学分析中的分类变量的清理与填充
我正在处理我的第一个机器学习问题,我正在努力清理我的数据集中的分类特性。我的目标是建立一个攀岩推荐系统。
问题1:
我有三列相关的列,它们有错误的信息:
现在的样子:
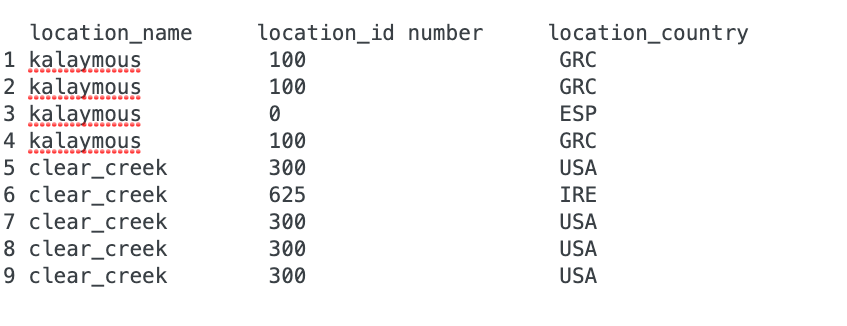
我想让它看起来像:
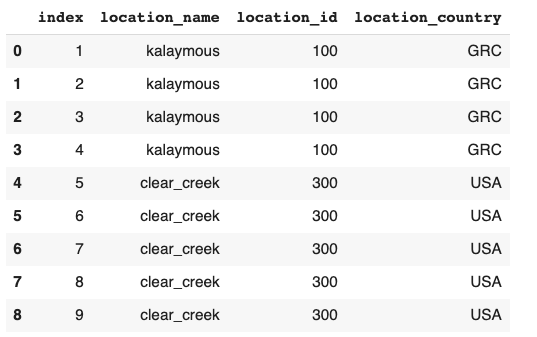
如果按位置名称分组,则有不同的location_id编号和与该名称相关联的国家。然而,每一项差异都有明显的赢家/明显多数。我有一个200万条目的数据集,location_id & location_country的模式是压倒一切的,它指向一个答案(例如:"300“和"USA”表示clear_creek)。
使用熊猫/巨蟒,我如何将我的数据集按location_name分组,根据这个位置名称计算location_id & location_country模式,然后用基于location_name的模式计算替换整个id和country列来清理数据?
我玩过groupby,替换,复制,但是我认为最终我需要创建一个函数来完成这个任务,而且我真的不知道从哪里开始。(我为我的编码幼稚而提前道歉)我知道一定有一个解决方案,我只需要被指引到正确的方向。
问题2:
另外,有谁建议在我的NaN类别(42,012/2百万)和location_country(46,890/2百万)列中填写location_name值?最好还是把它作为一个未知的价值来保存?我觉得根据频率来填写这些特性对我的数据集来说是一种可怕的偏见。
data = {'index': [1,2,3,4,5,6,7,8,9],
'location_name': ['kalaymous', 'kalaymous', 'kalaymous', 'kalaymous',
'clear_creek', 'clear_creek', 'clear_creek',
'clear_creek', 'clear_creek'],
'location_id': [100,100,0,100,300,625,300,300,300],
'location_country': ['GRC', 'GRC', 'ESP', 'GRC', 'USA', 'IRE',
'USA', 'USA', 'USA']}
df = pd.DataFrame.from_dict(data)*寻找它返回:
improved_data = {'index': [1,2,3,4,5,6,7,8,9],
'location_name': ['kalaymous', 'kalaymous', 'kalaymous', 'kalaymous',
'clear_creek', 'clear_creek', 'clear_creek',
'clear_creek', 'clear_creek'],
'location_id': [100,100,100,100,300,300,300,300,300],
'location_country': ['GRC', 'GRC', 'GRC', 'GRC', 'USA', 'USA',
'USA', 'USA', 'USA']}
new_df = pd.DataFrame.from_dict(improved_data)回答 3
Stack Overflow用户
发布于 2019-05-11 18:42:36
您可以通过使用transform计算模式来使用df.iat[]
df=(df[['location_name']].join(df.groupby('location_name').transform(lambda x: x.mode()
.iat[0])).reindex(df.columns,axis=1))
print(df) index location_name location_id location_country
0 1 kalaymous 100 GRC
1 1 kalaymous 100 GRC
2 1 kalaymous 100 GRC
3 1 kalaymous 100 GRC
4 5 clear_creek 300 USA
5 5 clear_creek 300 USA
6 5 clear_creek 300 USA
7 5 clear_creek 300 USA
8 5 clear_creek 300 USAStack Overflow用户
发布于 2019-05-11 18:24:47
我们可以将.agg与pd.Series.mode结合使用,并使用map将其转换回数据格式。
m1 = df.groupby('location_name')['location_id'].agg(pd.Series.mode)
m2 = df.groupby('location_name')['location_country'].agg(pd.Series.mode)
df['location_id'] = df['location_name'].map(m1)
df['location_country'] = df['location_name'].map(m2)print(df)
index location_name location_id location_country
0 1 kalaymous 100 GRC
1 2 kalaymous 100 GRC
2 3 kalaymous 100 GRC
3 4 kalaymous 100 GRC
4 5 clear_creek 300 USA
5 6 clear_creek 300 USA
6 7 clear_creek 300 USA
7 8 clear_creek 300 USA
8 9 clear_creek 300 USAStack Overflow用户
发布于 2019-05-11 17:47:13
正如Erfan提到的,对第一个问题的预期输出有一个视图是有帮助的。
对于第二个熊猫,有一个填充物方法。可以使用此方法填充NaN值。例如,要用“UNKNOWN_LOCATION”填充值,可以执行以下操作:
df.fillna('UNKNOWN_LOCATION')第一个问题见可能的解决办法:
df.groupby('location_name')[['location_id', 'location_country']].apply(lambda x: x.mode())https://stackoverflow.com/questions/56092440
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号