
如何为下面的场景编写正则表达式?
如何为下面的场景编写正则表达式?
提问于 2019-05-06 10:48:13
我喜欢写一个正则表达式,它必须满足所有这些例子。
而不使用^ like
[^ i|like|to|drink][\w+](\s*)(\w*)Regex:?
示例1:
sentence = i like to drink black tea
output = black tea示例2:
sentence: drink tea
output : tea示例3:
sentence = drink pomegranate juice
output = pomegranate juice回答 3
Stack Overflow用户
发布于 2019-05-06 10:55:00
尝试模式(?<=\bdrink\b)\s*(.*$) -> Lookbehind
Ex:
import re
data = ["i like to drink black tea", "drink tea", "drink pomegranate juice"]
for sentence in data:
m = re.search(r"(?<=\bdrink\b)\s*(.*$)", sentence)
if m:
print(m.group(1))输出:
black tea
tea
pomegranate juiceStack Overflow用户
发布于 2019-05-06 15:53:42
模式[^ i|like|to|drink][\w+](\s*)(\w*)使用匹配字符类中没有的任何字符的否定字符类。
我认为您的意思是使用一个使用交替和或|的分组结构,但这不会给您提供所需的匹配。
似乎你想要的是drink之后的东西。在这种情况下,您不需要查找,而只需要一个捕获组,其中您的值位于第一个组中:
\bdrink\b\s+(.*)$如果在要匹配的内容之前可以有多个单词,则可以使用替换:
\b(?:drink|have)\b\s+(.*)$另一种选择可以是在单词边界( \b )之间拆分单词"drink“。
import re
strings = ["i like to drink black tea", "drink tea", "drink pomegranate juice", "testdrinktest"]
for str in strings:
parts = re.split(r"\bdrink\b", str)
if len(parts) > 1:
print(parts[1])结果:
black tea
tea
pomegranate juiceStack Overflow用户
发布于 2019-05-08 06:27:54
这句话可以通过简单地创建两个捕获组来帮助您这样做:
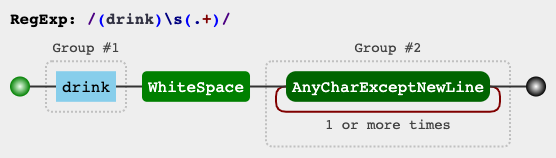
(drink)\s(.+)
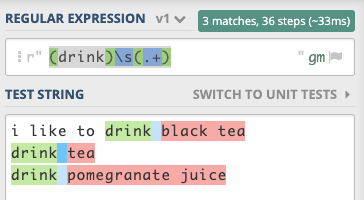
图表
此图显示了表达式的工作方式,您可以在这个链接中可视化其他表达式:
代码
# coding=utf8
# the above tag defines encoding for this document and is for Python 2.x compatibility
import re
regex = r"(drink)\s(.+)"
test_str = ("i like to drink black tea\n"
"drink tea\n"
"drink pomegranate juice\n")
matches = re.finditer(regex, test_str, re.MULTILINE)
for matchNum, match in enumerate(matches, start=1):
print ("Match {matchNum} was found at {start}-{end}: {match}".format(matchNum = matchNum, start = match.start(), end = match.end(), match = match.group()))
for groupNum in range(0, len(match.groups())):
groupNum = groupNum + 1
print ("Group {groupNum} found at {start}-{end}: {group}".format(groupNum = groupNum, start = match.start(groupNum), end = match.end(groupNum), group = match.group(groupNum)))
# Note: for Python 2.7 compatibility, use ur"" to prefix the regex and u"" to prefix the test string and substitution.输出
Match 1 was found at 10-25: drink black tea
Group 1 found at 10-15: drink
Group 2 found at 16-25: black tea
Match 2 was found at 26-35: drink tea
Group 1 found at 26-31: drink
Group 2 found at 32-35: tea
Match 3 was found at 36-59: drink pomegranate juice
Group 1 found at 36-41: drink
Group 2 found at 42-59: pomegranate juice页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/56003643
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号