
图像拼接
我录制了视频,而瓶子是rotated.Then,我从视频中获得帧,并从所有图像中切割中央块。

因此,对于所有的帧,我得到了以下图像:

我试过给他们缝制全景图,但结果很糟糕。我使用了以下程序:
import glob
#rom panorama import Panorama
import sys
import numpy
import imutils
import cv2
def readImages(imageString):
images = []
# Get images from arguments.
for i in range(0, len(imageString)):
img = cv2.imread(imageString[i])
images.append(img)
return images
def findAndDescribeFeatures(image):
# Getting gray image
grayImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Find and describe the features.
# Fast: sift = cv2.xfeatures2d.SURF_create()
sift = cv2.xfeatures2d.SIFT_create()
# Find interest points.
keypoints = sift.detect(grayImage, None)
# Computing features.
keypoints, features = sift.compute(grayImage, keypoints)
# Converting keypoints to numbers.
keypoints = numpy.float32([kp.pt for kp in keypoints])
return keypoints, features
def matchFeatures(featuresA, featuresB):
# Slow: featureMatcher = cv2.DescriptorMatcher_create("BruteForce")
featureMatcher = cv2.DescriptorMatcher_create("FlannBased")
matches = featureMatcher.knnMatch(featuresA, featuresB, k=2)
return matches
def generateHomography(allMatches, keypointsA, keypointsB, ratio, ransacRep):
if not allMatches:
return None
matches = []
for match in allMatches:
# Lowe's ratio test
if len(match) == 2 and (match[0].distance / match[1].distance) < ratio:
matches.append(match[0])
pointsA = numpy.float32([keypointsA[m.queryIdx] for m in matches])
pointsB = numpy.float32([keypointsB[m.trainIdx] for m in matches])
if len(pointsA) > 4:
H, status = cv2.findHomography(pointsA, pointsB, cv2.RANSAC, ransacRep)
return matches, H, status
else:
return None
paths = glob.glob("C:/Users/andre/Desktop/Panorama-master/frames/*.jpg")
images = readImages(paths[::-1])
while len(images) > 1:
imgR = images.pop()
imgL = images.pop()
interestsR, featuresR = findAndDescribeFeatures(imgR)
interestsL, featuresL = findAndDescribeFeatures(imgL)
try:
try:
allMatches = matchFeatures(featuresR, featuresL)
_, H, _ = generateHomography(allMatches, interestsR, interestsL, 0.75, 4.0)
result = cv2.warpPerspective(imgR, H,
(imgR.shape[1] + imgL.shape[1], imgR.shape[0]))
result[0:imgL.shape[0], 0:imgL.shape[1]] = imgL
images.append(result)
except TypeError:
pass
except cv2.error:
pass
result = imutils.resize(images[0], height=260)
cv2.imshow("Result", result)
cv2.imwrite("Result.jpg", result)
cv2.waitKey(0)我的结果是:

也许是有人知道热辣才能做得更好?我认为从车架上用小块可以消除圆度.但是..。
回答 1
Stack Overflow用户
发布于 2019-05-06 20:22:53
我设法取得了很好的成绩。我只是稍微重写了您的代码,下面是修改后的部分:
def generateTransformation(allMatches, keypointsA, keypointsB, ratio):
if not allMatches:
return None
matches = []
for match in allMatches:
# Lowe's ratio test
if len(match) == 2 and (match[0].distance / match[1].distance) < ratio:
matches.append(match[0])
pointsA = numpy.float32([keypointsA[m.queryIdx] for m in matches])
pointsB = numpy.float32([keypointsB[m.trainIdx] for m in matches])
if len(pointsA) > 2:
transformation = cv2.estimateRigidTransform(pointsA, pointsB, True)
if transformation is None or transformation.shape[1] < 1 or transformation.shape[0] < 1:
return None
return transformation
else:
return None
paths = glob.glob("a*.jpg")
images = readImages(paths[::-1])
result = images[0]
while len(images) > 1:
imgR = images.pop()
imgL = images.pop()
interestsR, featuresR = findAndDescribeFeatures(imgR)
interestsL, featuresL = findAndDescribeFeatures(imgL)
allMatches = matchFeatures(featuresR, featuresL)
transformation = generateTransformation(allMatches, interestsR, interestsL, 0.75)
if transformation is None or transformation[0, 2] < 0:
images.append(imgR)
continue
transformation[0, 0] = 1
transformation[1, 1] = 1
transformation[0, 1] = 0
transformation[1, 0] = 0
transformation[1, 2] = 0
result = cv2.warpAffine(imgR, transformation, (imgR.shape[1] +
int(transformation[0, 2] + 1), imgR.shape[0]))
result[:, :imgL.shape[1]] = imgL
cv2.imshow("R", result)
images.append(result)
cv2.waitKey(1)
cv2.imshow("Result", result)所以我改变的关键是图像的转换。我使用estimateRigidTransform()而不是findHomography()来计算图像的转换。从该转换矩阵中,我只提取x坐标转换,它位于生成的仿射变换矩阵 transformation的[0, 2]单元格中。我将其他转换矩阵元素设置为恒等变换(没有缩放、没有透视图、没有旋转或y平移)。然后,我将它传递给warpAffine(),以像对待warpPerspective()那样转换imgR。
你可以这样做,因为你有稳定的相机和旋转的物体位置,你用一个直视的物体捕捉。这意味着您不必进行任何透视图/缩放/旋转图像校正,只需通过x轴将它们“粘合”在一起。
我认为你的方法失败了,因为你实际上观察到瓶子有一个稍微向下倾斜的摄像头视图,或者瓶子不在屏幕的中间。我试着用图像来描述。我在瓶子上写了一些红色的文字。例如,该算法在捕获的圆形对象底部找到匹配点对(绿色)。注意,这个点不仅移动正确,而且对角也向上移动。然后,该程序计算转换,同时考虑到稍微向上移动的点。这种情况继续一帧一帧地恶化。
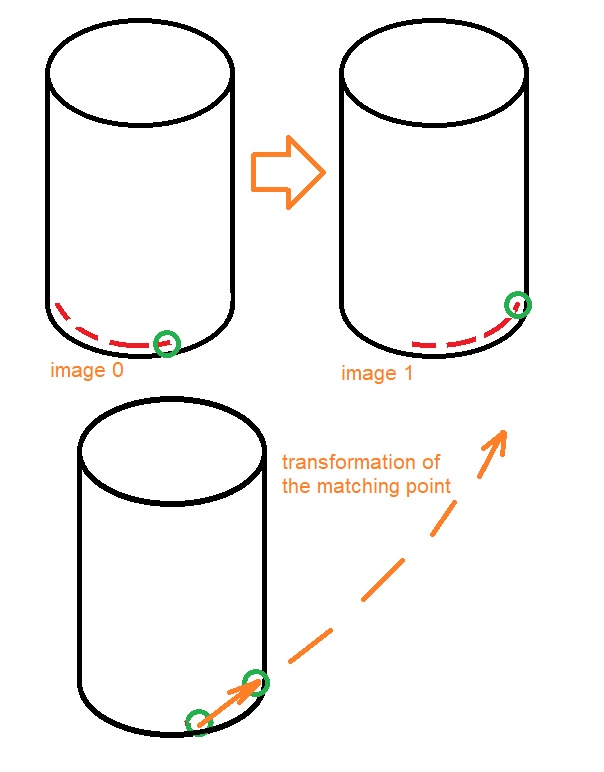
匹配图像点的识别也可能有点不准确,所以只提取x翻译会更好,因为您为算法提供了实际情况的线索。这使得它不太适用于另一种情况,但在您的情况下,它大大改善了结果。
另外,我还使用if transformation[0, 2] < 0检查筛选出一些不正确的结果(它只能旋转一个方向,如果这是负值的话,代码就不能工作)。
https://stackoverflow.com/questions/55996873
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号