
查找表示为列表的边
假设我们有一个二分图,其中节点被表示为列表。例如,假设二分图的节点为l1 = [1,2,3,4,5]和l2 = [6,7,8,9,10]是两个分区中的节点,边[1,8,'a',4,9,'b']表示为如图1所示的列表列表
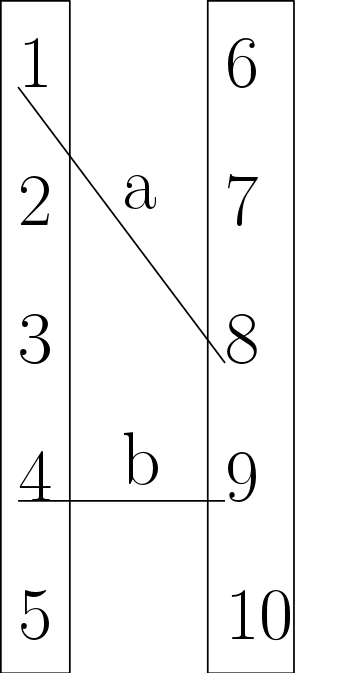
如果我们以某种方式合并了二分图的节点,并且现在用1表示为[[1,2,3], [4, 5]]和[[6,7] , [8, 9, 10]],那么在这个新的图中,如果原始图中的任何对之间都有边,那么这些群之间就会有边。例如,在上面的代码中,由于最初在1到8之间有一个边缘,所以在组a和[8,9,10]之间会有一个[8,9,10]边,如图1所示。如何在Python中找到新图中的边,什么是合适的数据结构表示,以及如何从这个原始图中找到产生的边?
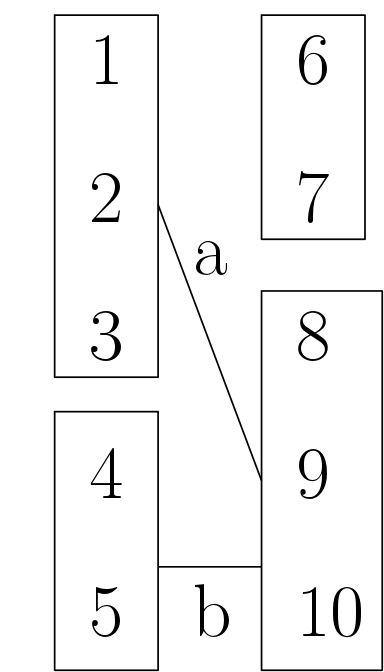
我已经为此使用了列表,但是问题是要找到这些边,我必须遍历新图中的所有节点来检查是否应该有一个边。有没有更有效的方法来做到这一点?
我试过的代码:
l1 = [1,2,3,4,5]
l2 = [6,7,8,9,10]
l3 = [[1,2,3], [4, 5]]
l4 = [[6,7] , [8, 9, 10]]
edges = [[1,8, 'a'], [4,9,'b']]
for e in edges:
for l in l3:
for k in l4:
if e[0] in l and e[1] in k:
print(e[0], e[1], e[2])回答 2
Stack Overflow用户
发布于 2019-05-04 12:32:58
让我们从获取包含特定值的组的索引开始。
def idx_group_in_list(value, list_) -> int:
"""e.g. value=2, list_=[[1,2],[3,4]] -> 0
because the value 2 is in the first (idx=0) inner list"""
for idx, l in enumerate(list_):
if value in l:
return idx
return -1在下面,我正在使用一个基于字典的解决方案。这使得检查边是否已经存在变得更容易了。
l3 = [[1, 2, 3], [4, 5]]
l4 = [[6, 7], [8, 9, 10]]
edges = [[1, 8, 'a'], [4, 9, 'b']]
new_edges = {}
for e in edges:
# left
l_idx = idx_group_in_list(e[0], l3)
r_idx = idx_group_in_list(e[1], l4)
if (l_idx, r_idx) in new_edges:
pass # two edges are squeezed. Maybe add some special stuff here
new_edges[(l_idx, r_idx)] = e[2]
print(new_edges)
expected_output = {(0, 1): 'a', (1, 1): 'b'}
print(expected_output == new_edges)编辑:
我做了一些非常简单的性能测试。大多数代码保持不变--我刚刚改变了方式,列表是生成的。
num_nodes_per_side = 1000
left = [[i] for i in range(num_nodes_per_side)]
right = [[i] for i in range(num_nodes_per_side, num_nodes_per_side*2)]
edges = [[i, j, 'a'] for i, j in zip(range(num_nodes_per_side), range(num_nodes_per_side, num_nodes_per_side*2))]
# result for num_nodes_per_side = 3
>>> left
[[0], [1], [2]]
>>> right
[[3], [4], [5]]
>>> edges
[[0, 3, 'a'], [1, 4, 'a'], [2, 5, 'a']]这意味着每个左组都有一个边到一个右组。下面是基于num_nodes_per_side的timeit结果。
- 10: 2.0693999999987778e-05
- 100: 0.0004394410000000404
- 1000: 0.042664883999999986
- 10000: 4.629786907
Stack Overflow用户
发布于 2019-05-04 12:49:11
为了获得更好的性能,可以将dict用于倒置指数(确保节点id是唯一的)。这使得搜索时间复杂度从O(n)提高到O(1),但重建数据结构需要付出一定的代价。下面是一个示例代码:
d3 = {node : idx for idx, l in enumerate(l3) for node in l}
d4 = {node : idx for idx, l in enumerate(l4) for node in l}
for node1, node2, name in edges:
if node1 in d3 and node2 in d4 or node2 in d3 and node1 in d4:
print(node1, node2, name)产出:
1 8 a
4 9 b如果您想要像@Uli Sotschok那样检查重复的边缘,那么这是简单的:
new_edges = {}
for node1, node2, name in edges:
if node1 in d3 and node2 in d4:
l_idx = d3[node1]
r_idx = d4[node2]
if (l_idx, r_idx) not in new_edges:
new_edges[(l_idx, r_idx)] = name
print(new_edges)
expected_output = {(0, 1): 'a', (1, 1): 'b'}
print(expected_output == new_edges)产出:
{(0, 1): 'a', (1, 1): 'b'}
Truehttps://stackoverflow.com/questions/55981931
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号