
刮擦蜘蛛只提取第一个表元素
刮擦蜘蛛只提取第一个表元素
提问于 2019-05-03 08:33:44
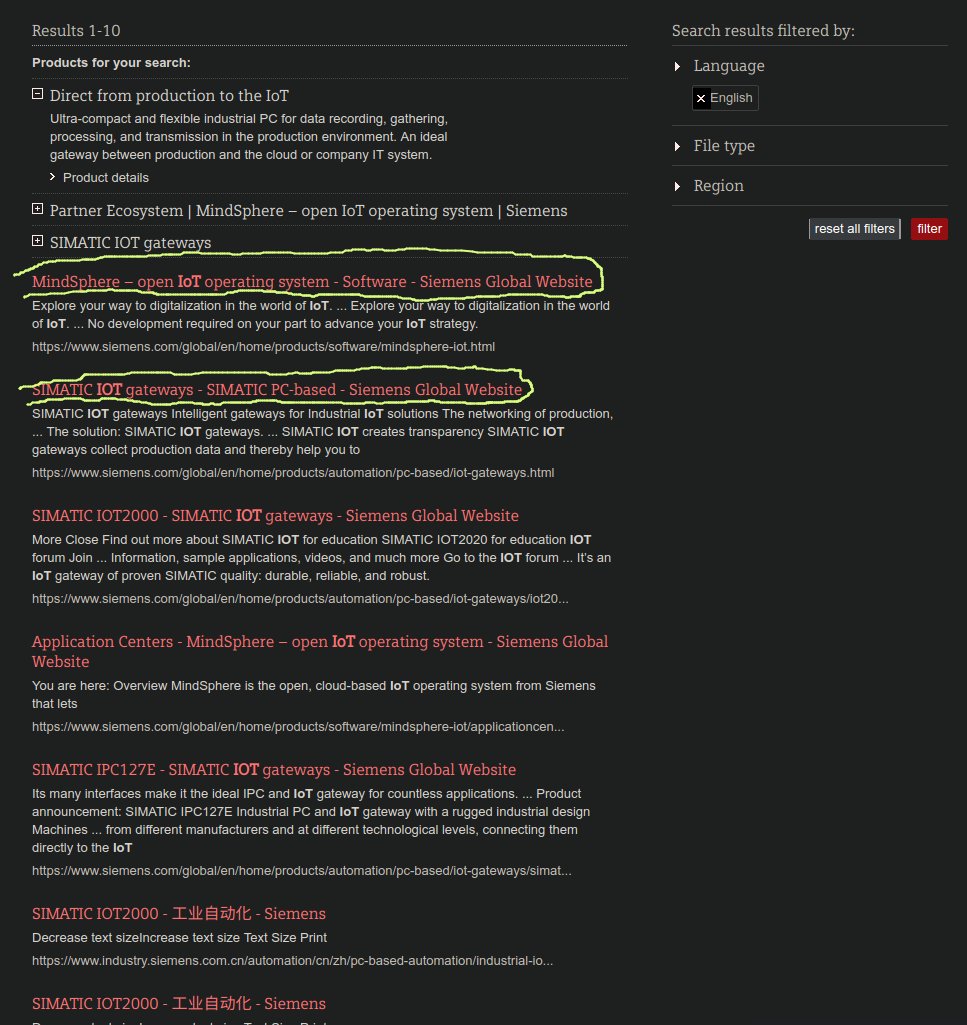
我试着刮这个网址:'search.siemens.com/en/?q=iot‘。作为开始,我只是对titel和类别感兴趣,在下面的截图中说明了这一点。然而,当我运行我的蜘蛛时,我只得到第一个元素:
{'titel': 'MindSphere – open ',
'category': ' operating system - Software - Siemens Global Website'}这是我的蜘蛛
import scrapy
class SiemensHtmlSpider(scrapy.Spider):
name = 'siemens_html'
allowed_domains = ['search.siemens.com/en/?q=iot']
start_urls = ['http://search.siemens.com/en/?q=iot/']
def parse(self, response):
#//dl[@id='search-resultlist']/dt/a
for element in response.xpath("//dl[@id='search-resultlist']"):
yield {
'titel': element.xpath('//dt/a/text()[1]').extract_first(),
'category': element.xpath('//dt/a/text()[2]').extract_first()
}我的截图是:
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-05-03 08:36:05
替换
yield {
'titel': element.xpath('//dt/a/text()[1]').extract_first(),
'category': element.xpath('//dt/a/text()[2]').extract_first()
}通过以下方式:
yield {
'titel': element.xpath('.//dt/a/text()[1]').extract_first(),
'category': element.xpath('.//dt/a/text()[2]').extract_first()
}注意xpath选择器前面的点,它们表示相对路径。
UPD:很小的提示,也可以检查您的allowed_domains值。它应该以这样的方式编写:allowed_domains = ['search.siemens.com']
UPD2:for循环中的主选择器也有问题,最好是在具体的块列表上有更多的预置和点。
for element in response.xpath("//dl[@id='search-resultlist']/dt"):
yield {
'titel': element.xpath('.//a/text()[1]').get(),
'category': element.xpath('.//a/text()[2]').get()
}页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55966072
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号