
为什么在配置Databricks连接之后"databricks-connect“不能工作?
我想使用IntelliJ IDEA直接在集群中运行我的Spark进程,所以我将按照下一个文档https://docs.azuredatabricks.net/user-guide/dev-tools/db-connect.html
配置完所有这些之后,我运行databricks-connect test,但是没有像文档所说的那样获得Scala。
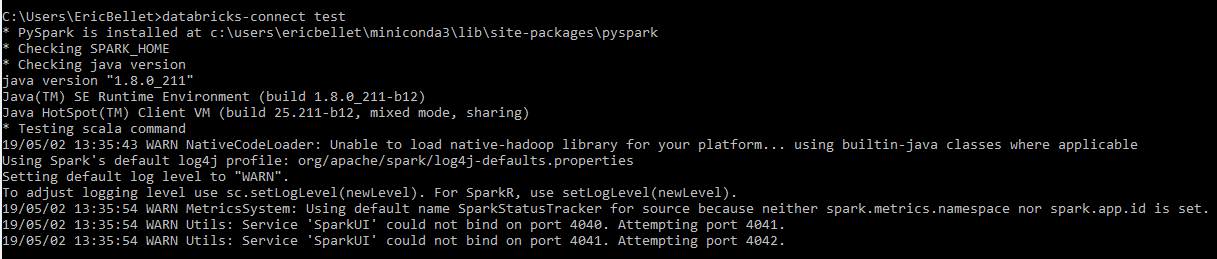
这就是我的集群配置。
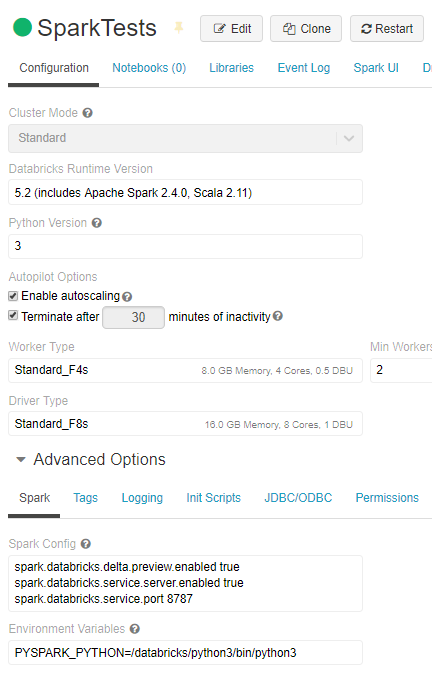
回答 4
Stack Overflow用户
发布于 2019-07-16 07:53:52
我解决了问题。问题在于所有工具的版本:
- 安装Java
下载并安装Java运行时版本8。
下载并安装Java开发工具包8。
- 安装Conda
您可以下载并安装完整的Anaconda,也可以使用miniconda。
- 下载WinUtils
这个讨厌的程序是Hadoop的一部分,需要Spark在Windows上工作。快速安装,打开Powershell (作为管理员)并运行(如果您在一个安全可靠的公司网络上,您可能需要手动下载exe ):
New-Item -Path "C:\Hadoop\Bin" -ItemType Directory -Force
Invoke-WebRequest -Uri https://github.com/steveloughran/winutils/raw/master/hadoop-2.7.1/bin/winutils.exe -OutFile "C:\Hadoop\Bin\winutils.exe"
[Environment]::SetEnvironmentVariable("HADOOP_HOME", "C:\Hadoop", "Machine")- 创建虚拟环境
我们现在是一个新的虚拟环境。我建议您在每个项目中创建一个环境。这允许我们安装不同版本的Databricks每个项目,并分别升级它们。
从开始菜单中找到Anaconda提示符。当它打开时,它将有一个默认提示符,类似于:
( base ) C:\User\User基本部件意味着您不是在虚拟环境中,而是在基本安装中。若要创建新环境,请执行以下操作:
conda create --name dbconnect python=3.5其中dbconnect是您的环境的名称,可以是您想要的。Databricks当前运行Python3.5-您的Python版本必须匹配。同样,这也是每个项目都有一个环境的另一个很好的理由,因为这可能会在未来发生变化。
- 现在激活环境: conda激活dbconnect
- 安装数据库-连接
你现在可以走了:
pip install -U databricks-connect==5.3.*
databricks-connect configure
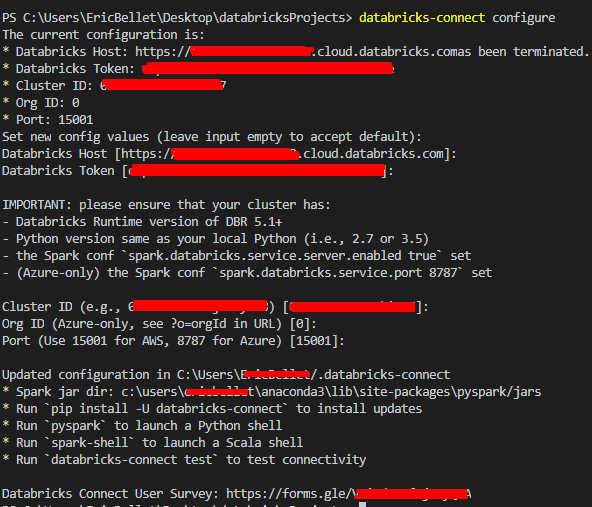
- 创建Databricks集群(在本例中,我使用了)
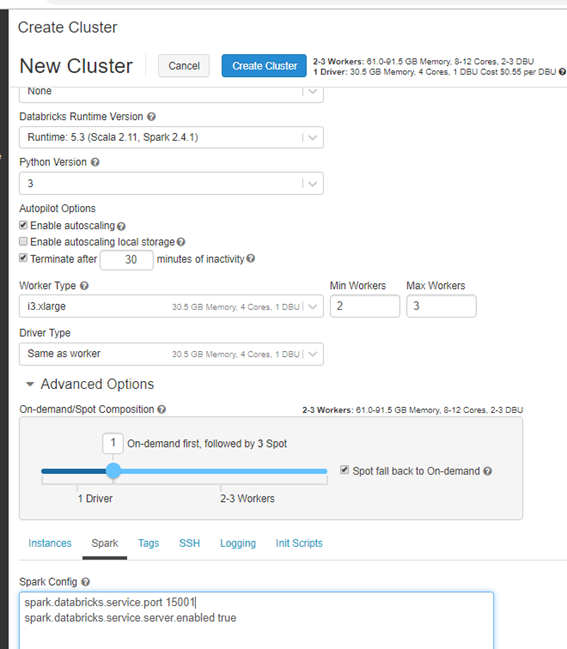
spark.databricks.service.server.enabled true
spark.databricks.service.port 15001 (Amazon 15001, Azure 8787)- 关闭Windows防御防火墙或允许访问。
Stack Overflow用户
发布于 2019-11-20 07:56:30
您的问题似乎是以下问题之一:( a)您指定了错误的端口(在Azure上必须是8787 )( b)您没有在Databricks集群c中打开端口)您没有正确安装winUtils (例如,您忘记放置环境变量
如果你有机会懂德语的话,这段youtube视频可能对你有帮助。(显示windows 10的完整安装过程)。
Stack Overflow用户
发布于 2019-05-24 14:15:17
尝试运行databricks示例,如:
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.getOrCreate()
print("Testing simple count")
# The Spark code will execute on the Databricks cluster.
print(spark.range(100).count())这对我有用。
也许他们会修复databricks-connect test
https://stackoverflow.com/questions/55951981
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号