
从ajax支持的弹出框中包含的工具提示中刮取文本
我知道以前也有人问过类似的问题,但似乎没有一个适用于这种特殊情况。我在几个网站上遇到了这个问题,所以我随机选择了the first page of SO's own tags list.。
如果您查看第一页的第一个条目,您会看到以下内容:
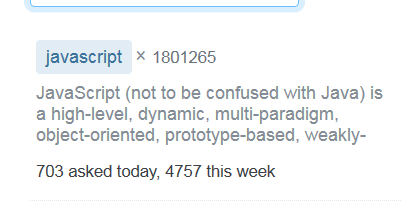
它显示标签描述的开头、问题总数以及今天和本周提出的问题数。这一信息很容易选择:
from selenium.webdriver import Chrome
driver = Chrome()
driver.get('https://stackoverflow.com/tags')例如,聚焦在JavaScript标记上:
dat = driver.find_elements_by_xpath("//*[contains(text(), 'week')]/ancestor::div[5]/div/div[1]/span/parent::*")
for i in dat:
print(i.text)输出:
javascript× 1801272
JavaScript (not to be confused with Java) is a high-level, dynamic, multi-paradigm, object-oriented, prototype-based, weakly-typed language used for both client-side and server-side scripting. Its pri…
703 asked today, 4757 this week现在情况变得更复杂了(至少对我来说是这样):如果您悬停在JavaScript标记上,就会得到这个弹出框:
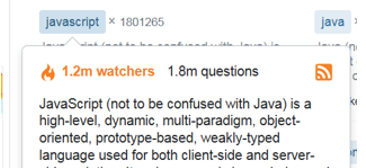
该框有完整的标签描述,以及(四舍五入)问题和观察者的数字。如果您悬停在“1.2米观察者”元素上,您将看到以下工具提示:
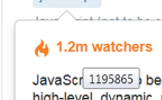
这是呼叫这个特定框的网址:
https://stackoverflow.com/tags/javascript/popup?_=1556571234452该目标项(以及问题总数)包含在此html中的title的span中:
<div class="-container">
<div class="-arrow js-source-arrow"></div>
<div class="mb12">
<span class="fc-orange-400 fw-bold mr8">
<svg aria-hidden="true" class="svg-icon va-text-top iconFire" width="18" height="18" viewBox="0 0 18 18"><path d="M7.48.01c.87 2.4.44 3.74-.57 4.77-1.06 1.16-2.76 2.02-3.93 3.7C1.4 10.76 1.13 15.72 6.8 17c-2.38-1.28-2.9-5-.32-7.3-.66 2.24.57 3.67 2.1 3.16 1.5-.52 2.5.58 2.46 1.84-.02.86-.33 1.6-1.22 2A6.17 6.17 0 0 0 15 10.56c0-3.14-2.74-3.56-1.36-6.2-1.64.14-2.2 1.24-2.04 3.03.1 1.2-1.11 2-2.02 1.47-.73-.45-.72-1.31-.07-1.96 1.36-1.36 1.9-4.52-2.03-6.88L7.45 0l.03.01z"/></svg>
<span title="1195903">1.2m</span> watchers
</span>
<span class="mr8"><span title="1801277">1.8m</span> questions</span>
<a class="float-right fc-orange-400" href="/feeds/tag/javascript" title="Add this tag to your RSS reader"><svg aria-hidden="true" class="svg-icon iconRss" width="18" height="18" viewBox="0 0 18 18"><path d="M1 3c0-1.1.9-2 2-2h12a2 2 0 0 1 2 2v12a2 2 0 0 1-2 2H3a2 2 0 0 1-2-2V3zm14.5 12C15.5 8.1 9.9 2.5 3 2.5V5a10 10 0 0 1 10 10h2.5zm-5 0A7.5 7.5 0 0 0 3 7.5V10a5 5 0 0 1 5 5h2.5zm-5 0A2.5 2.5 0 0 0 3 12.5V15h2.5z"/></svg></a>
</div>
<div>JavaScript (not to be confused with Java) is a high-level, dynamic, multi-paradigm, object-oriented, prototype-based, weakly-typed language used for both client-side and server-side scripting. Its primary use is in rendering and manipulating of web pages. Use this tag for questions regarding ECMAScript and its various dialects/implementations (excluding ActionScript and Google-Apps-Script). <a href="/questions/tagged/javascript">View tag</a></div></div>我想不出的是如何将所有这些信息放在一起,以便获得一个输出(或一个dataframe),这个输出看起来像这样,对于第一页中提到的所有标记:
Tag: JavaScript
Total questions: 1801277 #or whatever it is at the time this is performed
Watchers: 1195902 #same
.
.
etc.为了抢先可能的评论,请让我补充一下:我知道这样的搜索是有API的,但是(i)正如我提到的,我随机选择了SO的标签页,我想尽可能笼统地解决这个问题;(ii)如果我理解正确,this cannot be done with the SO API;和(iii)即使它可以,我仍然想学习如何使用刮取技术来完成它。
回答 1
Stack Overflow用户
发布于 2019-04-30 16:47:04
以下构造了检索该信息所需的最小url,然后从这些url中提取所需的信息,并插入作为列表row插入到最终列表results中的变量。最后的列表在最后被转换成一个数据文件。
的构造循环所有页面
https://stackoverflow.com/tags?page={}不确定您想要的数字,这周等,因为相同的时间周期,没有报告的每个标签。如果你能说明你想如何处理这个问题,我会更新答案。看起来单位可以是日,周或月(其中2个)。
我认为,在时间、期间、周/月等方面提出的问题都是动态加载的,因此您并不总是有两个度量。为此,我添加了一个if语句来处理这个问题。通过测试len of frequencies直到== 2,您可以一直发出请求直到获得该信息为止。
import requests
from bs4 import BeautifulSoup as bs
import urllib.parse
import pandas as pd
url = 'https://stackoverflow.com/tags/{}/popup'
page_url = 'https://stackoverflow.com/tags?page={}'
results = []
with requests.Session() as s:
r = s.get('https://stackoverflow.com/tags')
soup = bs(r.content, 'lxml')
num_pages = int(soup.select('.page-numbers')[-2].text)
for page in range(1, 3): # for page in range(1, num_pages):
frequency1 = []
frequency2 = []
if page > 1:
r = s.get(page_url.format(page))
soup = bs(r.content, 'lxml')
tags = [(item.text, urllib.parse.quote(item.text)) for item in soup.select('.post-tag')]
for item in soup.select('.stats-row'):
frequencies = item.select('a')
frequency1.append(frequencies[0].text)
if len(frequencies) == 2:
frequency2.append(frequencies[1].text)
else:
frequency2.append('Not loaded')
i = 0
for tag in tags:
r = s.get(url.format(tag[1]))
soup = bs(r.content, 'lxml')
description = soup.select_one('div:not([class])').text
stats = [item['title'] for item in soup.select('[title]')]
total_watchers = stats[0]
total_questions = stats[1]
row = [tag[0], description, total_watchers, total_questions, frequency1[i], frequency2[i]]
results.append(row)
i+=1
df = pd.DataFrame(results, columns = ['Tag', 'Description', 'Total Watchers', 'Total Questions', 'Frequency1', 'Frequency2'])
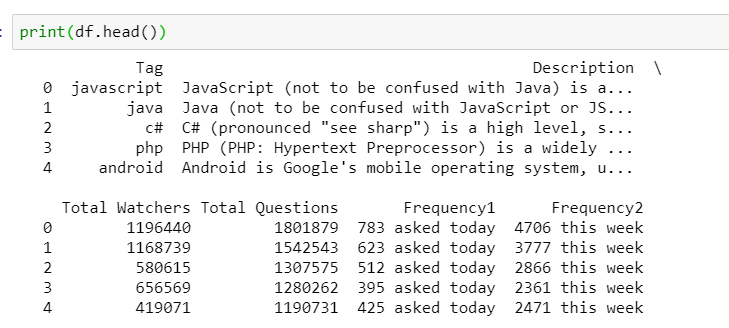
使用原始代码与Selenium相结合,以确保加载动态内容:
import requests
from bs4 import BeautifulSoup as bs
import urllib.parse
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
url = 'https://stackoverflow.com/tags/{}/popup'
page_url = 'https://stackoverflow.com/tags?page={}'
results = []
d = webdriver.Chrome()
with requests.Session() as s:
r = s.get('https://stackoverflow.com/tags')
soup = bs(r.content, 'lxml')
num_pages = int(soup.select('.page-numbers')[-2].text)
for page in range(1, 3): # for page in range(1, num_pages + 1):
if page > 1:
r = d.get(page_url.format(page))
WebDriverWait(d,10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.stats-row a')))
soup = bs(d.page_source, 'lxml')
tags = [(item.text, urllib.parse.quote(item.text)) for item in soup.select('.post-tag')]
how_many = [item.text for item in soup.select('.stats-row a')]
frequency1 = how_many[0::2]
frequency2 = how_many[1::2]
i = 0
for tag in tags:
r = s.get(url.format(tag[1]))
soup = bs(r.content, 'lxml')
description = soup.select_one('div:not([class])').text
stats = [item['title'] for item in soup.select('[title]')]
total_watchers = stats[0]
total_questions = stats[1]
row = [tag[0], description, total_watchers, total_questions, frequency1[i], frequency2[i]]
results.append(row)
i+=1
df = pd.DataFrame(results, columns = ['Tag', 'Description', 'Total Watchers', 'Total Questions', 'Frequency1', 'Frequency2'])
d.quit()
print(df.head())https://stackoverflow.com/questions/55924626
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号