
如何使用image()函数在R中绘制数据
如何使用image()函数在R中绘制数据
提问于 2019-04-21 17:17:38
我有一个临床数据集,我想用image()函数绘制它,看看我是否能够识别数据中的不同组。
该数据的结构是一个List of 2:56个样本和5000个基因表达。
当我使用image(lung)时,我所看到的只是一个橙色的小块,我没有看到图案或任何一群人站在我面前。
基本上,数据集中有四种类型的临床情况:结肠癌(13例)、小细胞(6例)等。
例如,我希望看到,与此数据集中的其他组/条件相比,具有6个样本的‘小单元’具有自己的模式。
load(url("https://github.com/hughng92/dataset/raw/master/lung.RData"))
rownames(lung)
image(lung)这就是我所看到的:
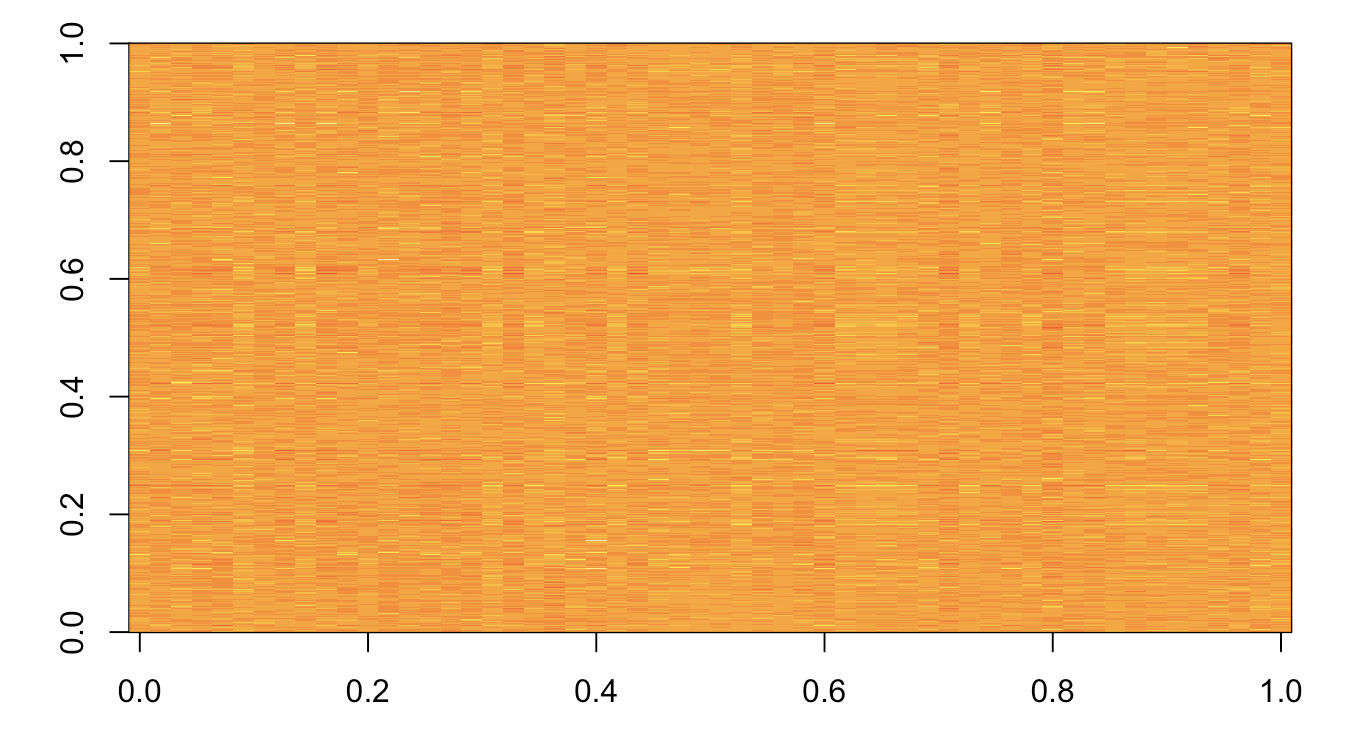
我想知道我是否可以从数据集中将这4种条件的四个不同的结合起来,这看起来就不一样了。
任何小费都会很棒!
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-04-21 19:34:32
我建议在将类似的类型重新排列在一起之后,查看图像输出。我想我现在在这些基因表达谱中看到了一些群体差异。具体来说,“正常”类的红色波段通常较少,尽管有一对“正常”是红色的,而其他的则不是。我认为这是有趣的,也不是特别令人惊讶,在正常的列(在图像中)的变化似乎比在每一种肿瘤类型内的变化要小。我有一位朋友,他是一位分子生物学家,他把肿瘤描述为“基因火车残骸”:
table( rownames( lung[order(rownames(lung)), ]))
Carcinoid Colon Normal SmallCell
20 13 17 6 image( lung[order(rownames(lung)), ])
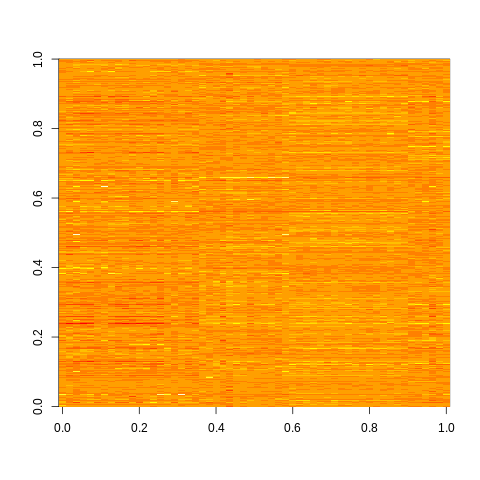
这将更好地显示类型分组的界限:
image( lung[order(rownames(lung)), ], xaxt="n")
axis(1, at=(cumsum( table( rownames( lung[order(rownames(lung)), ])))-1)/56 ,
labels=names(table( rownames( lung[order(rownames(lung)), ]))),las=2)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55784971
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号