
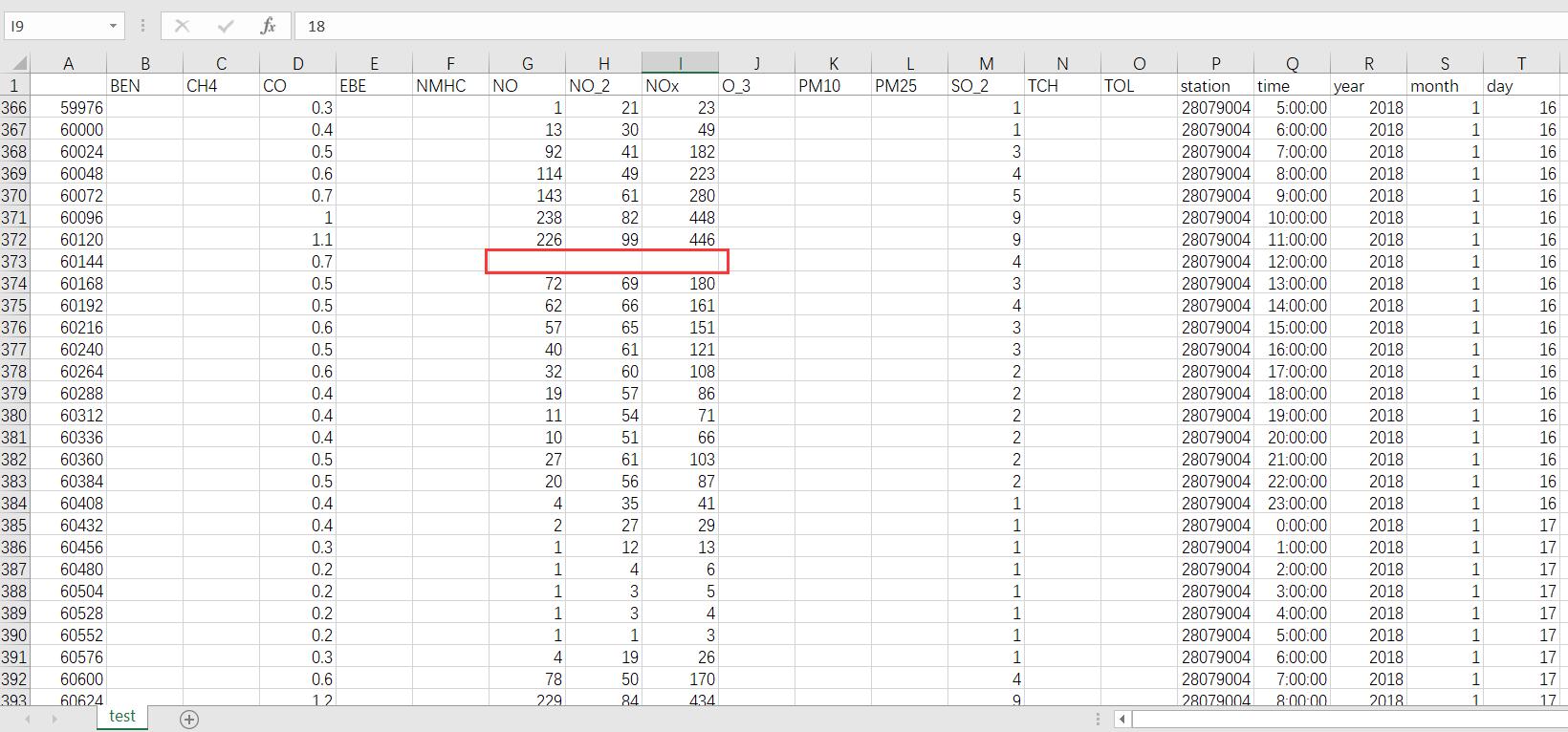
检查excel表中缺少的值。
我正在做我的数据可视化作业。首先,我必须检查我找到的数据集,如果有必要的话,我必须进行数据争论。这些数据由马德里空气质量的几个粒子指数组成,这些数据是由不同的观测站收集的。
我发现表中缺少一些值。如何通过工具(python或R或Tableau)快速检查丢失的值并替换这些值?
回答 3
Stack Overflow用户
发布于 2019-04-19 05:43:48
在Python中,您可以使用熊猫模块以DataFrame的形式加载Excel文件。在此之后,很容易替换NaN/missing值。假设您的excel名为madrid_air.xlsx
import pandas as pd
df = pd.read_excel('madrid_air.xlsx')发布这篇文章时,您将得到他们所称的DataFrame,它由excel文件中带有列名和索引的相同表格格式的数据组成。在DataFrame中,缺失的值将作为NaN值加载。因此,为了获得包含NaN值的行,
df_nan = df[df.isna()]df_nan将有包含NaN值的行。
现在,如果您想用0填充所有这些NaN值。
df_zerofill = df.fillna(0)df_zerofill将使用0替换所有NaNs的整个DataFrame。
为了具体地填充库仑,使用coumn名称。
df[['NO','NO_2']] = df[['NO','NO_2']].fillna(0)这将用0填充NO和NO_2列缺少的值。
阅读有关DataFrame:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html的更多信息
阅读有关处理DataFrames:data.html中丢失数据的更多信息
Stack Overflow用户
发布于 2019-04-19 05:26:19
有几个可供python处理excel电子表格的库。我最喜欢的是openpyxl。它将电子表格转换为数据,然后您可以通过它的坐标来处理特定的字段。它还能识别行和列的标签,这是非常有用的。当然,您也可以用它更新您的表。但是要小心,如果您正在使用损坏的代码,您的xlsx-文件可能会永久损坏。
Edit1:
import openpyxl
wb = openpyxl.load_workbook('filename.xlsx')
# if your worksheet is the first one in the workbook
ws = wb.get_sheet_names(wb.get_sheet_by_name()[0])
for row in ws.iter_rows('G{}:I{}'.format(ws.min_row,ws.max_row)):
for cell in row:
if cell.value is None:
cell.value = 0 Stack Overflow用户
发布于 2019-12-01 14:10:38
那么,在Tableau中,您可以创建一个工作表,在维度表(Blue )中拖放最低级别的粒度,并将列(作为度量)放在相同的图表中。
如果您的表是纯原子的,那么您将在右下角的工作表中得到一个响应,告诉您空值。单击它可以清除或替换工作簿数据中的这些特定值。
只是为了清洁,它不是“喜端”和编码方式,而是最简单的方式。
PS:您还可以通过"null“值过滤列,以检查Tableau的数据输入窗口中是否缺少值。
PS2:如果您想改变它的动态特性,您将需要使用如下公式:
IF ISNULL(Measure1)
THEN (Measure2) ˜ OR Another Formula
ELSE null
END https://stackoverflow.com/questions/55755989
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号