
慢AQL和数据类型转换,我如何提高我的AQL性能?
你好,ArangoDB社区
我已经用arangoimport (通过CSV)从sqlite导入了两个集合到ArangoDB。
接下来,我尝试运行一个简单的AQL来交叉引用这些集合(最终目标是通过边缘连接它们)。
Collection1有1682642份文件
Collection2有3,290个文档
以下AQL需要30秒才能完成:
FOR c1 IN Collection1
FOR c2 IN Collection2
FILTER c2._key == TO_STRING(c1.someField) return {"C2": c2._id, "C1": c1._id}如果像这样切换转换,则要花费很长时间(5分钟后放弃):
FOR c1 IN Collection1
FOR c2 IN Collection2
FILTER TO_NUMBER(c2._key) == c1.someField return {"C2": c2._id, "C1": c1._id}在"someField“上添加索引没有帮助。
Sqlite中相同的连接查询(从其中导入数据)需要不到1秒的时间完成。
一些想法和问题:
1)如何知道文档中字段的数据类型?
2) _key是一个字符串。我认为"someField“是一个数字(因为没有TO_STRING,就不会返回结果)。
3)在“TO_STRING”上添加someField是否有效地使字段上的索引不可用?
4)是否有办法使_key成为一个数字(最好是整数)。我认为比较数字更快,不是吗?
5)或者,我可以告诉arangoimport强制"someField“为字符串吗?
6)我还能做些什么让AQL跑得更快吗?
任何投入都要感谢,
埃拉德
回答 1
Stack Overflow用户
发布于 2019-04-16 11:49:41
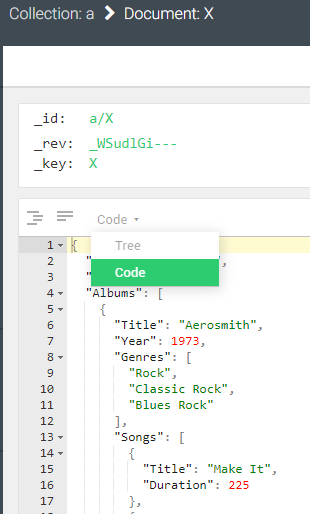
"Aerosmith"是字符串,1973是数字,类型是[ ... ]数组中的字符串,每首歌都是{ ... }对象。还有null、true和false文字。
对于确定属性的数据类型的编程方法,有类型检查函数,例如TYPENAME()将数据类型名称作为字符串返回。示例查询以计算属性someField的频率,数据类型为哪一种:
返回合并(用于c1 IN Collection1收集类型=TYPENAME(c1.omefield),计数为计数,返回{ type: COUNT })
_key始终是一个字符串。如果您不确定someField是什么,可以使用上面的查询。请分享这些信息。- 如果您将一个只在运行时(此处:属性)已知的值转换为另一个类型,则不会使用任何索引。只有当您按原样查询某个值时,才能进行索引查找。但是,您可以键入类型转换绑定变量和其他常量值,这在查询编译时是已知的。
- 不,文档键总是一个字符串。
_key属性上有一个索引(主索引),因此没有性能损失,因为它是一个字符串,而不是一个数值。 - arangoimport可以选择将数字字符串转换为数字,将
"null"转换为null,将"true"/"false"转换为布尔值(--convert),但没有选项强制属性成为字符串。有一个特征请求来添加指定所需数据类型的功能。 如果您希望数字字符串保持字符串,请使用--convert false关闭自动转换。如果值是源文件中的数字(而不是引号),则可以在导入文件之前对其进行调整。还可以使用一次性AQL查询将属性转换为特定的数据类型: 使用{ c1 : TO_STRING(someField) } IN Collection1在Collection1中更新文档 - 我假设在SQLite中,主键是一个整数值,因此也引用它(外键)。因为主键必须是ArangoDB中的字符串,所以引用也需要字符串类型。更改文档以将外键也存储为字符串。将散列索引添加到Collection1 on
someField(用于联接的字段)。然后,这个查询应该是快速的,并返回预期的结果: 对于c1 IN Collection1 IN c2 IN Collection2 FILTER c2._key == c1.某个字段返回{ C2: c2._id,C1: c1._id }
https://stackoverflow.com/questions/55702362
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号