
火花动态窗口计算
火花动态窗口计算
提问于 2019-04-10 11:15:36
下面是可用于计算max_price的销售数据。Max_price逻辑
Max(last 3 weeks price)
对于前3周没有数据的前3周,最高价格为
max of(week 1 , week 2 , week 3)
在下面的例子中,最大值(等级5,6 ,7)。
如何在火花中实现相同的窗口函数?
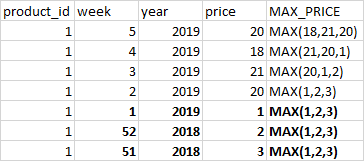
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-04-10 16:30:39
下面是使用PySpark窗口的解决方案: lead/udf。
请注意,我把排名5,6,7的价格改为1,2,3,以区别于其他值来解释。这个逻辑就是选择你解释的东西。
max_price_udf = udf(lambda prices_list: max(prices_list), IntegerType())
df = spark.createDataFrame([(1, 5, 2019,1,20),(2, 4, 2019,2,18),
(3, 3, 2019,3,21),(4, 2, 2019,4,20),
(5, 1, 2019,5,1),(6, 52, 2018,6,2),
(7, 51, 2018,7,3)], ["product_id", "week", "year","rank","price"])
window = Window.orderBy(col("year").desc(),col("week").desc())
df = df.withColumn("prices_list", array([coalesce(lead(col("price"),x, None).over(window),lead(col("price"),x-3, None).over(window)) for x in range(1, 4)]))
df = df.withColumn("max_price",max_price_udf(col("prices_list")))
df.show()哪种结果
+----------+----+----+----+-----+------------+---------+
|product_id|week|year|rank|price| prices_list|max_price|
+----------+----+----+----+-----+------------+---------+
| 1| 5|2019| 1| 20|[18, 21, 20]| 21|
| 2| 4|2019| 2| 18| [21, 20, 1]| 21|
| 3| 3|2019| 3| 21| [20, 1, 2]| 20|
| 4| 2|2019| 4| 20| [1, 2, 3]| 3|
| 5| 1|2019| 5| 1| [2, 3, 1]| 3|
| 6| 52|2018| 6| 2| [3, 1, 2]| 3|
| 7| 51|2018| 7| 3| [1, 2, 3]| 3|
+----------+----+----+----+-----+------------+---------+以下是Scala中的解决方案
var df = Seq((1, 5, 2019, 1, 20), (2, 4, 2019, 2, 18),
(3, 3, 2019, 3, 21), (4, 2, 2019, 4, 20),
(5, 1, 2019, 5, 1), (6, 52, 2018, 6, 2),
(7, 51, 2018, 7, 3)).toDF("product_id", "week", "year", "rank", "price")
val window = Window.orderBy($"year".desc, $"week".desc)
df = df.withColumn("max_price", greatest((for (x <- 1 to 3) yield coalesce(lead(col("price"), x, null).over(window), lead(col("price"), x - 3, null).over(window))):_*))
df.show()Stack Overflow用户
发布于 2019-04-10 19:34:14
您可以将SQL窗口函数与combined ()结合使用。当SQL窗口函数的行数少于3行时,您将考虑当前行,甚至前面的行。因此,需要在内部子查询中计算lag1_price、lag2_price。在外部查询中,您可以使用row_count值并通过传入针对2,1,0的相应值的lag1、lag2和当前价格来使用最大()函数,并获得最大值。
看看这个:
val df = Seq((1, 5, 2019,1,20),(2, 4, 2019,2,18),
(3, 3, 2019,3,21),(4, 2, 2019,4,20),
(5, 1, 2019,5,1),(6, 52, 2018,6,2),
(7, 51, 2018,7,3)).toDF("product_id", "week", "year","rank","price")
df.createOrReplaceTempView("sales")
val df2 = spark.sql("""
select product_id, week, year, price,
count(*) over(order by year desc, week desc rows between 1 following and 3 following ) as count_row,
lag(price) over(order by year desc, week desc ) as lag1_price,
sum(price) over(order by year desc, week desc rows between 2 preceding and 2 preceding ) as lag2_price,
max(price) over(order by year desc, week desc rows between 1 following and 3 following ) as max_price1 from sales
""")
df2.show(false)
df2.createOrReplaceTempView("sales_inner")
spark.sql("""
select product_id, week, year, price,
case
when count_row=2 then greatest(price,max_price1)
when count_row=1 then greatest(price,lag1_price,max_price1)
when count_row=0 then greatest(price,lag1_price,lag2_price)
else max_price1
end as max_price
from sales_inner
""").show(false)结果:
+----------+----+----+-----+---------+----------+----------+----------+
|product_id|week|year|price|count_row|lag1_price|lag2_price|max_price1|
+----------+----+----+-----+---------+----------+----------+----------+
|1 |5 |2019|20 |3 |null |null |21 |
|2 |4 |2019|18 |3 |20 |null |21 |
|3 |3 |2019|21 |3 |18 |20 |20 |
|4 |2 |2019|20 |3 |21 |18 |3 |
|5 |1 |2019|1 |2 |20 |21 |3 |
|6 |52 |2018|2 |1 |1 |20 |3 |
|7 |51 |2018|3 |0 |2 |1 |null |
+----------+----+----+-----+---------+----------+----------+----------+
+----------+----+----+-----+---------+
|product_id|week|year|price|max_price|
+----------+----+----+-----+---------+
|1 |5 |2019|20 |21 |
|2 |4 |2019|18 |21 |
|3 |3 |2019|21 |20 |
|4 |2 |2019|20 |3 |
|5 |1 |2019|1 |3 |
|6 |52 |2018|2 |3 |
|7 |51 |2018|3 |3 |
+----------+----+----+-----+---------+页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55611203
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号