
Python:从FuzzyWuzzy ExtractOne()返回Pandas FuzzyWuzzy
我有两个Pandas DataFrames (人名),一个小行(200+行),另一个很大(100k+行)。它们都有相似的头,但是大的头也有一个唯一的ID,如下所示:
Small: LST_NM, FRST_NM, CITY
Big: LST_NM, FRST_NM, CITY, UNIQUE_ID小:df2 = pd.DataFrame([['Doe','John','New York'], ['Obama', 'Barack', 'New York']], columns = ['FRST_NM', 'LST_NM', 'CITY_NM'])

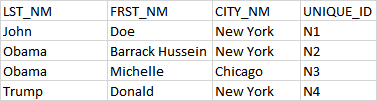
大:df = pd.DataFrame([['Doe','John','New York', 'N1'], ['Obama', 'Barack Hussein', 'New York', 'N2'], ['Obama', 'Michelle', 'Chicago', 'N3'], ['Trump', 'Donald', 'New York', 'N4']], columns = ['FRST_NM', 'LST_NM', 'CITY_NM', 'UNIQUE_ID'])
我使用以下代码:
import itertools
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
import time
import pandas as pd
import multiprocessing as mp
from unidecode import unidecode
import re
#read the CSV files;
df = pd.read_csv("BIG.csv", encoding="utf-8")
df2 = pd.read_csv("SMALL.csv", encoding="utf-8")
#create function to clean the columns
def clean_column(column):
column = unidecode(column)
column = re.sub('\n', ' ', column)
column = re.sub('-', ' ', column)
column = re.sub('/', ' ', column)
column = re.sub("'", '', column)
column = re.sub(",", '', column)
column = re.sub(":", ' ', column)
column = re.sub(' +', ' ', column)
column = column.strip().strip('"').strip("'").lower().strip()
if not column :
column = None
return column
#Normalize, create FULL_NM by combining FRST_NM / LST_NM and then create MIN_CITY as the first three chars from CITY_NM:
df['FULL_NM'] = (df['LST_NM'] + ' ' + df['FRST_NM']).apply(lambda x: fuzz._process_and_sort(clean_column(x), True, True))
df['MIN_CITY'] = (df['CITY_NM']).astype(str).apply(lambda x: clean_column(x[:3]))
df2['FULL_NM'] = (df2['LST_NM'] + ' ' + df2['FRST_NM']).apply(lambda x: fuzz._process_and_sort(clean_column(x), True, True))
df2['MIN_CITY'] = (df2['CITY_NM']).astype(str).apply(lambda x: clean_column(x[:3]))
#create match1 function; it uses the FULL_NM as lookup field
def match1(x, choices, scorer, cutoff):
match = process.extractOne(x['FULL_NM'], choices=choices.loc[choices['MIN_CITY'] == x['MIN_CITY'],'FULL_NM'],
scorer=scorer,
score_cutoff=cutoff)
if match:
return match[0]
#and finally... create the MATCH_NM column by applying match1 function as following:
df2['MATCH_NAME'] = df2.apply(match1, args=(df, fuzz.token_set_ratio, 80), axis=1)我想查找从大到小的信息,带来UNIQUE_ID。为了加速这个过程,我创建了更小的块(使用前三个城市字母)。这个新列(在两个DataFrames中创建)被命名为MIN_CITY。
上面的代码运行良好,但它只带来匹配的名称(MATCH_NAME)。我不想逆转(从小到大,然后过滤)。如何从UNIQUE_ID ()获得process.ExtractOne?我需要指出的是,我对Python / Pandas / FuzzyWuzzy非常陌生。
回答 1
Stack Overflow用户
发布于 2019-04-08 10:02:06
请查一下模糊匹配器
from fuzzymatcher import link_table, fuzzy_left_join
left_on = ['FULL_NM']
right_on = ['FULL_NM']
fuzzy_left_join(df2, df, left_on, right_on)给出一张表:
best_match_score __id_left __id_right FRST_NM_left LST_NM_left CITY_NM_left FULL_NM_left MIN_CITY_left MATCH_NAME FRST_NM_right LST_NM_right CITY_NM_right UNIQUE_ID FULL_NM_right MIN_CITY_right
0 0.167755 0_left 0_right Doe John New York doe john new doe john Doe John New York N1 doe john new
1 0.081166 1_left 1_right Obama Barack New York barack obama new barack hussein obama Obama Barack Hussein New York N2 barack hussein obama new这里有一些示例。
如果必须坚持使用fuzzy_wuzzy.process.extractOne,则可以匹配并从匹配的名称中找到unique_id,如下所示:
def match1(x, choices, scorer, cutoff):
match = process.extractOne(x['FULL_NM'], choices=choices.loc[choices['MIN_CITY'] == x['MIN_CITY'],'FULL_NM'],
scorer=scorer,
score_cutoff=cutoff)
if match:
return choices[choices['FULL_NM'] == 'doe john'].UNIQUE_ID[0]https://stackoverflow.com/questions/55568849
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号