
图中缺失的后验分布
图中缺失的后验分布
提问于 2019-03-25 00:35:48
我试图用R来计算后验分布,并为我的先验、可能性和后验分布生成一个三角图图。我有一个先验分布π_1 (θ) = Be (1.5,1.5)。
这是我的R码:
n <- 25
X <- 16
a <- 1.5
b <- 1.5
grid <- seq(0,1,.01)
like <- dbinom(X,n,grid)
like
like <- like/sum(like)
like
prior <- dbeta(grid,a,b)
prior1 <- prior/sum(prior)
post <- like*prior
post <- post/sum(post)它确实给了我一个Triplot,但我也想得到我的后验分布的值,但是在我的代码中似乎缺少了一些东西。
为了澄清,我正在寻找上述先验分布的的θ的后分布。
此外,我还努力:
install.packages("LearnBayes")
library("LearnBayes")
prior = c( a= 1.5, b = 1.5 )
data = c( s = 25, f = 16 )
triplot(prior,data)它给了我一个完美的三角图,但也没有后部的价值。
回答 1
Stack Overflow用户
发布于 2019-04-02 15:33:11
它在那里,但只是先验是如此微弱的信息(Beta[a=1.5, b=1.5]是几乎一致的),似然函数与后验差别很小。一种直观的思考方法是,a+b-2是1,这意味着先前的观察实际上只支持先前的1,而N是25,这意味着数据得到25个观测的支持。这导致数据在贡献信息方面占主导地位。
改变先前的更强将使差别更加明显:
prior <- c(a=10, b=10)
data <- c(s=25, f=16)
triplot(prior, data)
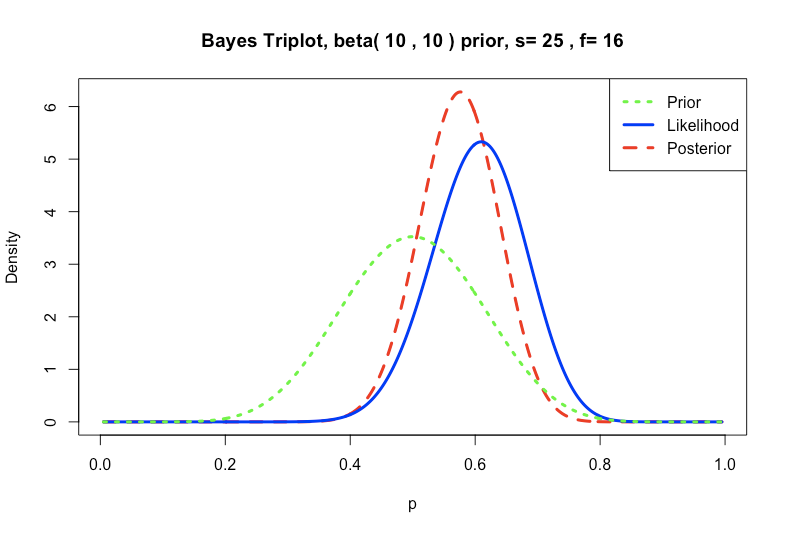
注意,如果这是可用的所有信息,那么使用弱信息先验没有什么问题。当观测数据足够大时,它应该占主导地位。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55329958
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号