
在缺少值的dataframe中为所有可能的组自定义分组
我有一张代表一组产品的数据。我需要在这些产品中找到所有的复制产品。如果产品具有相同的product_type、color和size ->,则它们是重复的。如果我没有问题的话,这将是一个简单的df.groupby('product_type','color','size')行:一些值丢失了。现在我必须找到所有可能的产品组,它们之间可能是重复的。--这意味着某些元素可以出现在多个组中。
让我举例说明:
import pandas as pd
def main():
df = pd.DataFrame({'product_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
'product_type': ['shirt', 'shirt', 'shirt', 'shirt', 'shirt', 'hat', 'hat', 'hat', 'hat', 'hat', 'hat', ],
'color': [None, None, None, 'red', 'blue', None, 'blue', 'blue', 'blue', 'red', 'red', ],
'size': [None, 's', 'xl', None, None, 's', None, 's', 'xl', None, 'xl', ],
})
print df
if __name__ == '__main__':
main()对于这个数据文件:
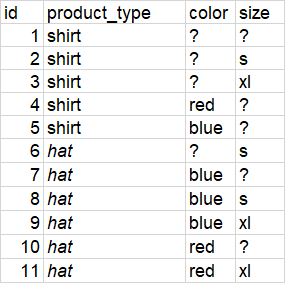
我需要这个结果-可能重复的产品清单为每个可能的组(只采取最大的超级组):
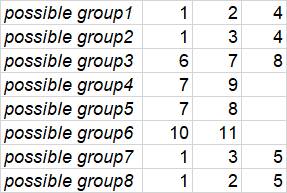
例如,让我们使用id=1的“恤”这个产品没有颜色或尺寸,所以他可以出现在一个可能的“复制组”与衬衫#2 (它有尺寸"s“,但没有颜色)和衬衫#4 (有颜色”红色“,但没有大小)。因此,这三件衬衫(1,2,4)可能是复制相同颜色的“红色”和"s“。
我试图通过循环遍历所有可能的缺失值组合来实现它,但它感觉是错误和复杂的。
有没有办法得到预期的结果?
回答 1
Stack Overflow用户
发布于 2019-03-19 05:11:54
寻找所有组合的问题可能具有指数复杂性;
from itertools import product
def get_possible_combinations(df, columns=['size', 'product_type', 'color']):
col_vals = []
for col in columns:
col_vals.append(df.loc[~df.loc[:, col].isnull(), col].unique().tolist())
for comb in product(*col_vals):
df_ = df.copy()
for val, col in zip(comb, columns):
df_.loc[:, col].fillna(val, inplace=True)
yield df_.groupby(columns)因此,我们可以将此函数应用于df
resulting_groups = []
for g in get_possible_combinations(df):
sorted_groups = [ind.tolist() for a, ind in g.groups.items()]
resulting_groups.append(sorted_groups)
resulting_groups = sum(resulting_groups, [])
sorted(list(set(map(tuple, resulting_groups))), key=len, reverse=True)(5、6、7)、(0、2、3)、(0、1、3)、(0、1、4)、(0、2、4)、(5、9)、(6、7)、(6、8)、(5、7)、(9、10)、(1 )、(2 )、(8 )、(3 )、(9 )、(4 )、(10 )、(5,),(7,)
这几乎和你想要的一样。
https://stackoverflow.com/questions/55233805
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号