
Workbooks.OpenText忽略FieldInfo列参数
我有下面的行来导入csv格式文件。
Workbooks.OpenText Filename:=sPath, DataType:=xlDelimited, Comma:=True, FieldInfo:=Array(Array(18, 5), Array(19, 5)), Local:=True从微软的文档这里中,如果FieldInfo是分隔的,它就不需要按任何顺序排列。
列说明符可以是任意顺序的。如果输入数据中没有特定列的列说明符,则使用General设置解析该列。
然而,excel似乎将第一个数组作为第一列,第二数组作为第二列,不管我在第一个参数Array(Array(x, 5), Array(y, 5))中添加了什么。因此,要达到第18和19栏,我必须这样做,这是不漂亮的:
Workbooks.OpenText Filename:=sPath, DataType:=xlDelimited, Comma:=True, _
FieldInfo:=Array(Array(1, 1), _
Array(2, 1), _
Array(3, 1), _
Array(4, 1), _
Array(5, 1), _
Array(6, 1), _
Array(7, 1), _
Array(8, 1), _
Array(9, 1), _
Array(10, 1), _
Array(11, 1), _
Array(12, 1), _
Array(13, 1), _
Array(14, 1), _
Array(15, 1), _
Array(16, 1), _
Array(17, 1), _
Array(18, 5), _
Array(19, 5)), _
Local:=Truecsv文件示例数据:
fill_c1,pick_n2,po_num3,quanti4,addres5,cust_s6,color_7,size_d8,style9,shipto10,shipto11,addres12,addres13,city14,state15,zipcod16,custom17,start_18,end_da19,udford20
"52","1","2","000000001","000000000000000000000000000000","6","Z","XS","7","","","","","","","","M",20190310,20190318,"CF3"
"52","1","2","000000002","000000000000000000000000000000","6","Z","S","7","","","","","","","","M","20190310","20190318","CF3"回答 2
Stack Overflow用户
发布于 2019-03-14 15:24:37
我能够使用.txt文件和Tab=True再现这个问题。
Workbooks.OpenText Filename:=Path & "Testfile.txt", DataType:=xlDelimited, Tab:=True, FieldInfo:=Array(Array(18, 9), Array(19, 9)), Local:=True通过使用值9 (xlSkipColumn),我试图省略列18和19,但忽略了第1和第2列(Test1和Test2):
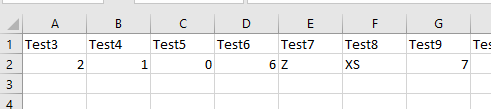
文档用于清楚地表明“列说明符可以按任何顺序排列”,但这看起来是不正确的。第一个数组的第一个元素总是列1,第二个数组的第一个元素总是列2,在所有数组迭代之后,其余的列将被解析为General设置。
海事组织,在我看来,这是一只虫子。如果不是错误,那么文档就会非常混乱,需要重新编写。
Stack Overflow用户
发布于 2019-03-15 00:20:29
这看起来确实是一个错误,或者文档有误导性。避免丑陋代码的一个解决办法是导入文本文件,而不对其进行分隔,并使用TextToColumns将其拆分。类似的事情(奇怪的是,这似乎是可行的):
Workbooks.OpenText Filename:=sPath, DataType:=xlDelimited, Comma:=False
Columns("A:A").TextToColumns Destination:=Range("A1"), _
DataType:=xlDelimited, _
TextQualifier:=xlDoubleQuote, _
ConsecutiveDelimiter:=False, _
FieldInfo:=Array(Array(18, 4), Array(19, 4))https://stackoverflow.com/questions/55151207
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号