
如何计算所有特征与目标变量(二进制分类器,python 3)的相关性?
如何计算所有特征与目标变量(二进制分类器,python 3)的相关性?
提问于 2019-03-12 02:44:26
我想在python中计算我的所有特性(所有浮点类型)和类标签(二进制,0或1)之间的相关性。此外,我还想绘制这些数据,以便按类可视化它们的分布。
这是必要的,这样我就可以找到与单个标签相结合的特性,并找出它们的真正重要性。注意,我不想要成对的特征相关性,并且我的分类器是二进制的。
我已经尝试了以下(从类似的帖子在堆栈溢出),但这不是我想要的。
df.drop("Target", axis=1).apply(lambda x: x.corr(df.Target)) 请在附图中看到发行版的外观,其中一个是特性(来自Weka)。
一个特性的类分布()
任何反馈都是非常感谢的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-03-12 05:52:45
关联不应该用于分类变量。有关更多解释,请参见这里
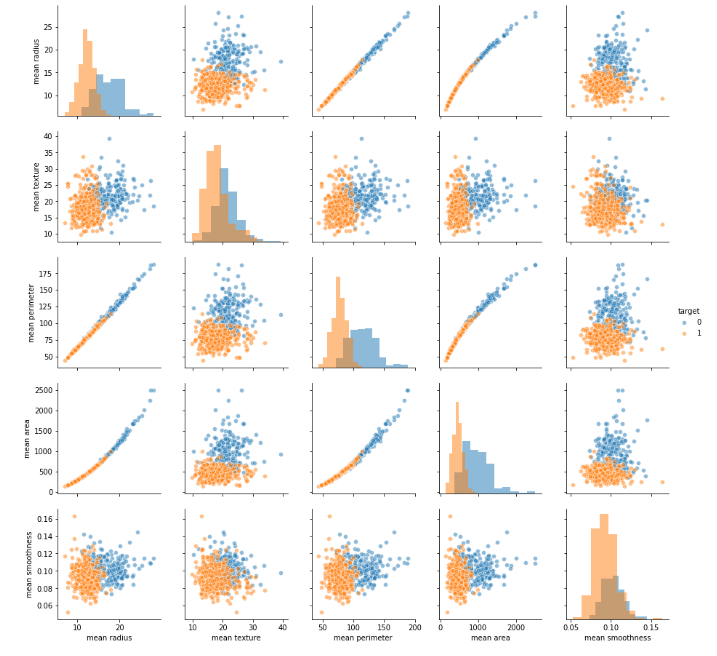
您可以通过以下方法理解自变量和目标变量之间的关系。
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer(return_X_y=False)
import pandas as pd
df=pd.DataFrame(data.data[:,:5])
df.columns = data.feature_names[:5]
df['target'] = data.target.astype(str)
import seaborn as sns;
import matplotlib.pyplot as plt
g= sns.pairplot(df,hue = 'target', diag_kind= 'hist',
vars=df.columns[:-1],
plot_kws=dict(alpha=0.5),
diag_kws=dict(alpha=0.5))
plt.show()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/55113349
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号