
需要DAX公式来排序和消除重复项
我有一个枢轴表,看起来是这样的:
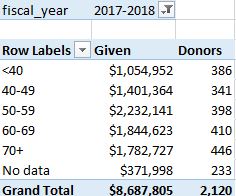
问题:捐款者和捐赠者一样,总人数不多。这是因为捐献者的年龄范围是根据每一份礼物的日期来确定的,在一年的时间里,捐献者可以跨越年龄范围。
要求:我想要一个DAX公式限制捐助者在一个范围内。在一个理想的世界里,这将是基于他们的年龄范围在一年的大部分时间,但我会满足于只是任意保留其中之一。我相信SQL,您可以通过分区和排序来实现这一点。
下表样本:
| Donation_ID | Donor_ID | Donation_Date | Amount | age at time of gift | summary_range |
|-------------|----------|---------------|--------|---------------------|---------------|
| 1 | 100 | 3/15/2017 | 400 | 39 | <40 |
| 2 | 101 | 4/3/2017 | 50 | 69 | 60-69 |
| 3 | 100 | 5/30/2017 | 15 | 40 | 40-49 |
| 4 | 101 | 10/7/2017 | 20 | 69 | 60-69 |
| 5 | 100 | 1/23/2018 | 220 | 40 | 40-49 |
| 6 | 101 | 2/17/2018 | 25 | 70 | 70+ |UPDATE -我有以下代码要在DaxStudio中工作。但是它在Excel中失败了,它说:“摘要不能有外部过滤器上下文。”根据下面一页底部的脚注,这显然只是Excel的一个限制:https://www.sqlbi.com/articles/introducing-summarizecolumns/
EVALUATE(
// filter context of the pivot table EXCEPT no filter on age range
var fc = CALCULATETABLE(
data_table,
data_table[Donation_Date] >= date(2017,3,1),
data_table[Donation_Date] <= date(2018,2,28)
)
var hh = SUMMARIZECOLUMNS(data_table[Donor_ID], data_table[summary_range],data_table[age at time of gift], fc)
var ranked =
ADDCOLUMNS(
hh,
"RankByAge",
RANKX (
FILTER(
SUMMARIZECOLUMNS(
data_table[Donor_ID],data_table[age at time of gift],
hh
),
data_table[Donor_ID] = EARLIER(data_table[Donor_ID])
),
data_table[age at time of gift],
,
desc,
DENSE
)
)
return
// ultimately need to count the rows rather than just return them
// the second criteria would come from the filter context in Excel
FILTER(ranked, [RankByAge] = 1 && [summary_range] = "<40" )
)回答 1
Stack Overflow用户
发布于 2019-03-10 21:13:49
我认为最简单的方法是创建几个计算过的列来代替。
让我们为每个捐献者创造一个独特的年龄,为他们的最新捐赠选择他们的年龄。
MaxAge =
CALCULATE(
MAX(data_table[ageattimeofgift]),
ALLEXCEPT(data_table, data_table[Donor_ID])
)然后查找与这个年龄相关的范围。
MaxRange =
LOOKUPVALUE(
data_table[summary_range],
data_table[ageattimeofgift],
data_table[MaxAge]
)在透视表中使用这个而不是summary_range。
(注意:如果您愿意,也可以按财政年度划分MaxAge,以便在单独查看年份时,捐赠者可以在组间移动。)
一种更动态的方法是使用一种可以在过滤器上下文中读取的度量。
Distinct Donors =
VAR CurrentRange =
VALUES ( data_table[summary_range] )
VAR Summary =
SUMMARIZE (
ALLSELECTED ( data_table ),
data_table[Donor_ID],
"MaxAge", MAX ( data_table[ageattimeofgift] ),
"Amount", SUM ( data_table[Amount] )
)
VAR MaxRange =
ADDCOLUMNS (
Summary,
"MaxRange",
LOOKUPVALUE (
data_table[summary_range],
data_table[ageattimeofgift], [MaxAge]
)
)
RETURN
COUNTROWS(
FILTER(
MaxRange,
CONTAINS(
CurrentRange,
[summary_range],
[MaxRange]
)
))
注意,我使用的是SUMMARIZE而不是SUMMARIZECOLUMNS。有关这些功能在不同环境中的差异和限制的更多信息,请参考这篇文章。
您可以在RETURN之后使用下面的代码来获得相应的金额。
SUMX ( FILTER ( MaxRange, [MaxRange] IN CurrentRange ), [Amount] )注意:上面的IN语法是一个较新的特性。为了向后兼容性使用CONTAINS函数。
https://stackoverflow.com/questions/55071734
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号