
根据VTune的说法,使用OpenMP时“平均物理核心利用率”很低,不确定更大的情况是什么
我一直在优化射线追踪器,为了提高速度,我使用了OpenMP,大致如下(C++):
Accelerator accelerator; // Has the data to make tracing way faster
Rays rays; // Makes the rays so they're ready to go
#pragma omp parallel for
for (int y = 0; y < window->height; y++) {
for (int x = 0; x < window->width; x++) {
Ray& ray = rays.get(x, y);
accelerator.trace(ray);
}
}我在一个6核/12线程CPU上获得了4.85x的性能。我想我会得到更多,也许是6-8倍.特别是当这占用了应用程序处理时间的99%时。
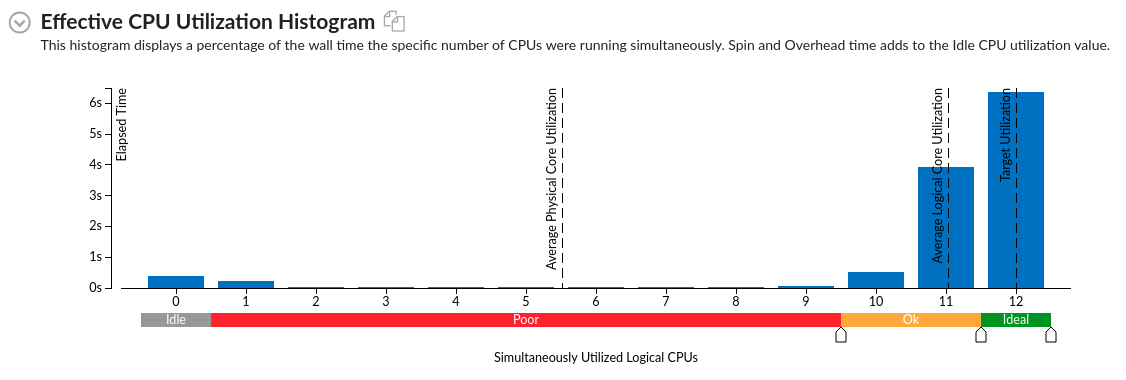
我想知道我的性能瓶颈在哪里,所以我打开了VTune并对其进行了分析。请注意,我对分析很陌生,所以这可能是正常的,但这是我得到的图表:
特别是,这是第二大消费时间:

其中58%是微结构的使用。
为了自己解决这个问题,我去寻找这方面的信息,但我能找到的最多的是英特尔的VTune维基页面:
平均物理岩心利用率 度量描述 该度量通过应用程序的计算显示平均物理核利用率。旋转和头顶时间不算在内。理想的平均CPU利用率等于物理CPU核的数量。
我不知道这是想告诉我什么,这就引出了我的问题:
这样的结果正常吗?还是有什么地方出了问题?,只看到4.8倍的加速比(相对于理论上的最大值12.0),对于那些令人尴尬的平行的东西,还行吗?虽然射线追踪本身可能会因为射线在任何地方反射而变得不友好,但我已经尽我所能来压缩内存,尽可能地保持缓存友好,使用使用SIMD进行计算的库,从文献中做了无数的实现来加快速度,避免了尽可能多的分支,并且不做递归。我还并行化了射线,这样就没有错误的共享AFAIK,因为每一行都是由一个线程完成的,所以不应该为任何线程编写任何缓存行(特别是因为射线遍历都是const)。此外,框架缓冲区是主要的行,所以我希望错误的共享不会成为一个问题。
我不知道分析器是否会选择使用OpenMP线程的主循环,这是一个预期的结果,或者我是否犯了某种新手错误,并且没有得到我想要的吞吐量。我还检查了它是否生成了12个线程,而OpenMP则这样做了。
我想是我用OpenMP搞砸了吗?从我收集的数据来看,平均物理核心利用率应该接近平均逻辑核心利用率,但我几乎肯定不知道我在说什么。
回答 1
Stack Overflow用户
发布于 2019-03-25 15:38:06
Imho,你做得对,你高估了并行执行的效率。您没有详细说明您正在使用的体系结构(CPU、内存等),也没有给出代码.但是简单地说,我认为超过4.8倍的速度会达到内存带宽限制,所以RAM速度是瓶颈。
为什么?
正如您所说的,光线跟踪并不难并行运行,而且您做得很好,所以如果CPU不是100%繁忙,我猜是您的内存控制器。假设你在追踪一个模型(三角形)?体素?)这是在RAM中,您的射线需要读取比特模型时,检查命中。您应该检查您的最大RAM带,然后除以12 (线程),然后除以它的射线数每秒.当你追踪到大量射线时,即使是40 GB/s也“不多”。这就是为什么GPU是射线追踪的更好选择的原因。
长话短说,我建议你试着分析一下内存使用情况。
https://stackoverflow.com/questions/55056661
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号