
随机森林中树数与OOB误差的划分
我拟合了一个随机森林模型。我使用过randomForest和ranger软件包。我没有调整森林中的树数,我只留下了默认的编号,即500。现在我想看看是否足够了,也就是错误是否达到了一个平台。因此,我相信我需要提取单个树,随机抽取100,200,300,400,最后500棵树,从它们中提取oob树,并计算出100,200,……的OOB错误。连续的树木。然后,我可以绘制OOB错误与树数之间的关系。我发现randomForest::getTree和ranger::treeInfo返回一个树的data.frame,但我不知道那里是什么。更重要的是,ranger::treeInfo返回50% NAs的数据帧,整个输出甚至更难读取。所以我的问题是:
- 如果我已经有一个有500棵树的随机森林,那么如何绘制OOB错误与森林中使用的树数之间的关系呢?
- 为什么
ranger::treeInfo有50%的NAs,而实际上只有这些行有预测?
下面是一个很小的例子:
mpg2 <- mpg %>%
mutate(is_suv = as.factor(class == 'suv')) %>%
select(-class)
mpg_model <- ranger::ranger(is_suv ~ ., data = mpg2)
ranger::treeInfo(mpg_model, tree = 100)回答 2
Stack Overflow用户
发布于 2019-03-04 13:15:15
我认为您要寻找的只是plot(.),如下面的示例所示:
library(randomForest)
set.seed(71)
iris.rf <- randomForest(Species ~ ., data=iris, importance = TRUE, proximity=TRUE)
# plot the model
plot(iris.rf)
# add legend to know which is which
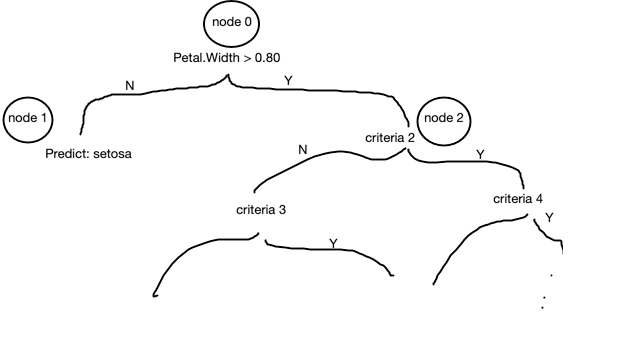
legend("top", colnames(iris.rf$err.rate), fill=1:ncol(iris.rf$err.rate))至于randomForest::getTree和ranger::treeInfo,它们与OOB无关,它们只是简单地描述了所选树的大纲,即哪些节点是在哪些条件上分裂的,哪些节点是连接到哪个节点上的,每个包使用的表示略有不同,例如,下面的内容来自ranger::treeInfo
nodeID leftChild rightChild splitvarID splitvarName splitval terminal prediction
1 0 1 2 4 Petal.Width 0.80 FALSE <NA>
2 1 NA NA NA <NA> NA TRUE setosa它基本上是这样描述的:
Stack Overflow用户
发布于 2022-11-07 12:28:40
使用上面相同的虹膜例子,我认为类似的东西会起作用。
lev <- c("OOB", levels(iris.rf$y))
err <- c()
for (i in 1:length(lev)) {
err <- c(err, iris.rf$err.rate[,lev[i]])
}
oob.error.data <- data.frame(
Trees = rep(1:nrow(iris.rf$err.rate), times = 1 + (length(levels(iris.rf$y)))),
Type = rep(biolev, each = nrow(iris.rf$err.rate)),
Error = err)
ggplot(data = oob.error.data, aes(x = Trees, y = Error)) +
geom_line(aes(color = Type))查看youtube上的乔希·斯塔默的例子 of randomForest in R以获取详细信息
`
https://stackoverflow.com/questions/54977780
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号