
PCA图约简维数
PCA图约简维数
提问于 2019-02-27 17:51:00
我尝试使用PCA技术进行聚类。
在我的例子中,我有n部电影的用户所做的评论。我以这种方式创建了一个表用户x电影:
User Movie
0 1 2 3 4
0 2 0 5 0 0
1 0 1 1 0 0
2 0 5 5 5 0其中0如果用户不看电影,1-5如果他评论从1到5星。形状为(6040,3706)
我将数据规范化,并在我使用此代码用于PCA之后(来自sklearn)
pca = PCA(0.7)
pca_result = pca.fit_transform(X_std)
a = pca_result[:,0]
b = pca_result[:,1] 我使用0.7作为集群,因为我的累积解释方差
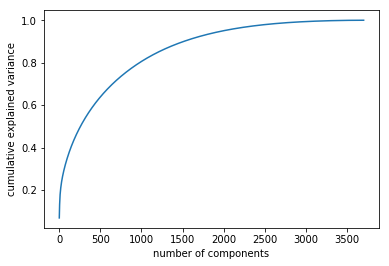
因此,对我来说,它的表现值是0.7,我的新形状是(6040,650)。
当我看到这个维度是这样的(但我不认为是非常有意义的)
fig = plt.figure(figsize = (20,16))
ax = fig.add_subplot(111)
ax.scatter(a,b, alpha = 1)
plt.title('Method: PCA')
plt.show()但是用这种方法,我把A放在X轴上,B放在Y轴上,所以我认为只使用两个维度(因为我看到了所有的例子都是二维的)。
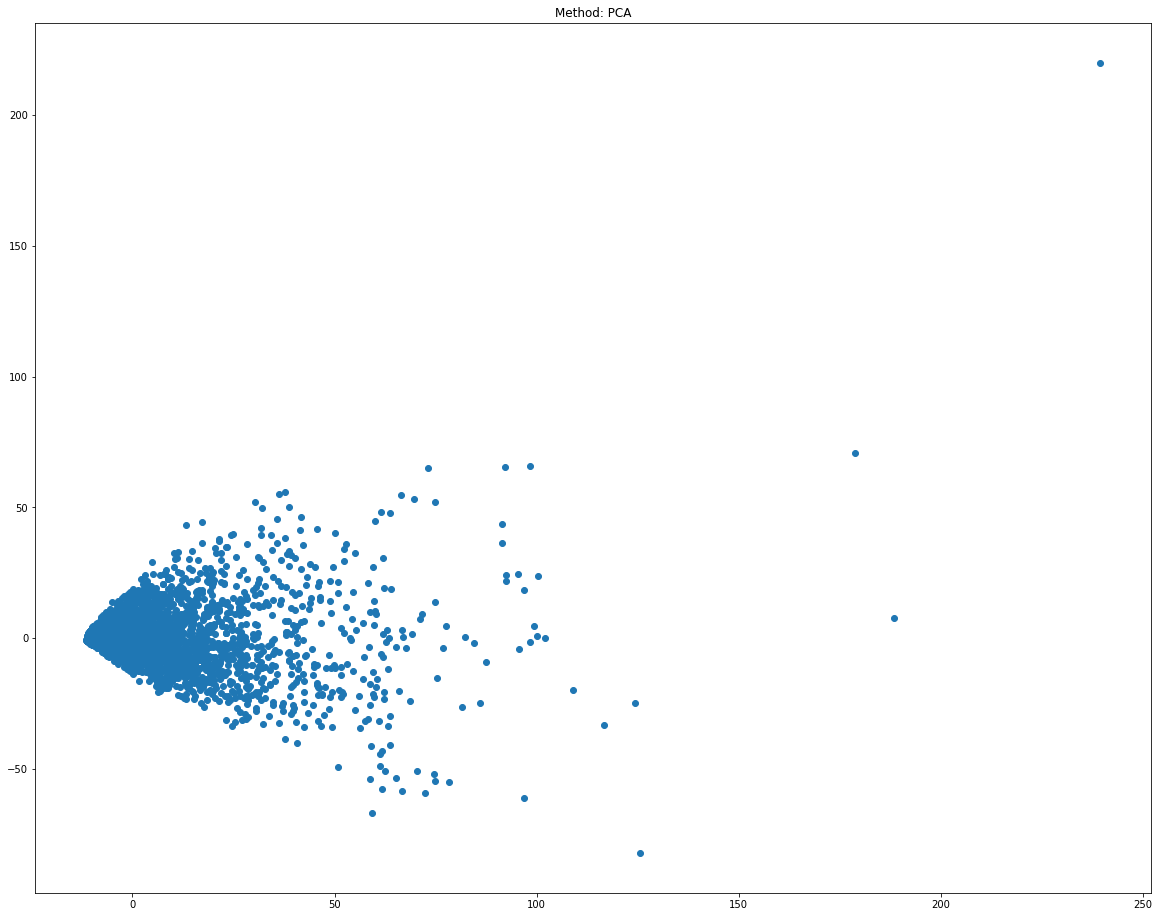
,所以我的问题是,我没有绘制出所有的维度?(在我的例子中,650个剩余维度?),我做错了什么?
也许我的问题是愚蠢的,但我试着去理解这个话题。
回答 1
Stack Overflow用户
发布于 2019-03-28 01:52:42
不要使用0来编码丢失的值(特别是不使用PCA)。
这是最大的差别到5,所以本质上你现在假设用户讨厌所有他们没有评分的电影。
我不知道是否有PCA的任何变体可以处理丢失的数据。通常,它似乎假定您拥有所有的值。所以你可能需要选择其他算法。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54911601
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号