
熊猫群按agg/对组中不同行的不同功能应用
熊猫群按agg/对组中不同行的不同功能应用
提问于 2019-02-25 14:30:28
我试图通过聚合来执行一个组。我的假人Dataframe看起来是这样的:
print (df)
ID Industry Value 1 Value 2
0 1 Finance 0.25 99
1 1 Finance 0.50 73
2 1 Finance 0.25 53
3 1 Teaching 0.75 80
4 1 Teaching 0.25 78
5 1 Teaching 0.50 99
6 2 Finance 0.50 75
7 2 Finance 0.25 56
8 2 Finance 0.25 80
9 2 Teaching 0.50 79
10 3 Finance 0.25 61
11 3 Finance 0.75 87
12 3 Finance 0.75 97
13 3 Finance 0.25 99
14 3 Finance 0.25 76
15 3 Teaching 0.25 73
16 3 Teaching 0.75 68
17 3 Teaching 0.25 59
18 3 Teaching 0.25 60我想按ID和工业进行分组,我想创建一个新的字段,名为"Expected“。预期将等于:
- 如果是组的第一行,则值1+值2
- 如果它是组中该行的组期望值中的任何其他行减去当前行的值(值1*值2),则期望值如下所示:
如果可能的话我想避免循环。任何帮助都会受到赞赏,因为使用iloc、groupby agg、groupby transform的多次尝试对我来说都是短暂的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2019-02-25 14:40:21
首先由numpy.where和duplicated设置新列,然后使用DataFrameGroupBy.cumsum
m = df.duplicated(['ID','Industry'])
df['new'] = np.where(m, -df['Value 1'] * df['Value 2'], df['Value 1'] + df['Value 2'])
df['new'] = df.groupby(['ID','Industry'])['new'].cumsum()
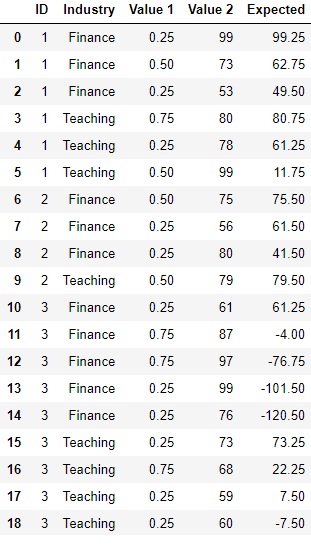
print (df)
ID Industry Value 1 Value 2 new
0 1 Finance 0.25 99 99.25
1 1 Finance 0.50 73 62.75
2 1 Finance 0.25 53 49.50
3 1 Teaching 0.75 80 80.75
4 1 Teaching 0.25 78 61.25
5 1 Teaching 0.50 99 11.75
6 2 Finance 0.50 75 75.50
7 2 Finance 0.25 56 61.50
8 2 Finance 0.25 80 41.50
9 2 Teaching 0.50 79 79.50
10 3 Finance 0.25 61 61.25
11 3 Finance 0.75 87 -4.00
12 3 Finance 0.75 97 -76.75
13 3 Finance 0.25 99 -101.50
14 3 Finance 0.25 76 -120.50
15 3 Teaching 0.25 73 73.25
16 3 Teaching 0.75 68 22.25
17 3 Teaching 0.25 59 7.50
18 3 Teaching 0.25 60 -7.50页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54868421
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号