
在Python中用多个高斯曲线拟合数据
在Python中用多个高斯曲线拟合数据
提问于 2019-02-24 10:38:02
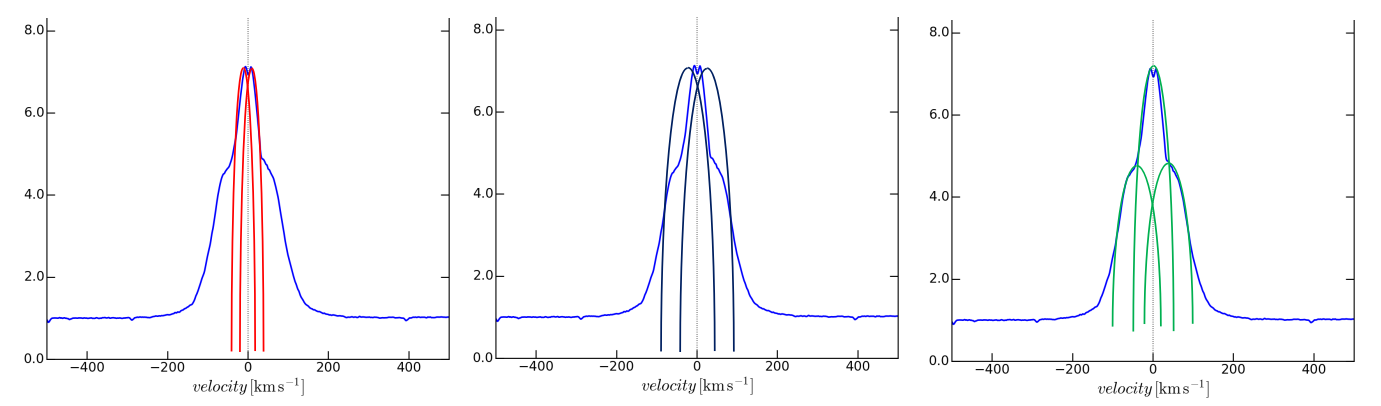
我有一些数据(data.txt),并试图用Python编写一个代码,以不同的方式将它们与高斯配置文件相匹配,以获得和比较每种情况下的峰值分离和下曲线区域:
- 有两个高斯轮廓(考虑顶部的小峰,忽略肩部;红色轮廓)
- 有两个高斯轮廓(忽略顶部的小峰,考虑顶部和肩部的整个单峰;黑色轮廓)
- 有三个高斯轮廓(考虑肩膀上两个较短的峰值;绿色轮廓)
我试过几个脚本,但都失败了。
这些情节中的个人资料是假的,我只是添加了它们,以更好地说明我的意思。
回答 2
Stack Overflow用户
回答已采纳
发布于 2019-02-24 11:25:23
解决这一问题的办法如下:
- 定义要与数据相匹配的函数,即应该在其中的所有组件的总和。在你的例子中,这是多重高斯。
- 查找参数的初始猜测。
- 将您的拟合功能与数据相匹配,使用您喜欢的策略。
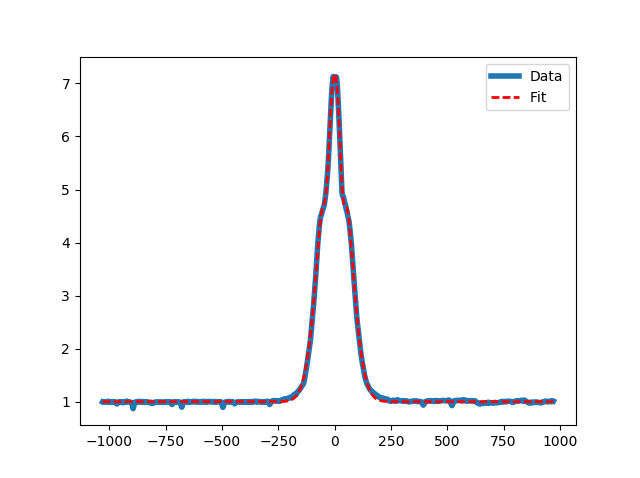
下面是一个非常简单的例子,用SciPy的curve_fit方法拟合三个高斯分量和一个连续偏移量。剩下的就交给你了。这应该可以让你找出其他的案例。请注意,最初的猜测通常很重要,所以最好以某种方式进行合理的猜测,以尽可能接近最优值。
码
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
import numpy as np
def gaussian(x, A, x0, sig):
return A*np.exp(-(x-x0)**2/(2*sig**2))
def multi_gaussian(x, *pars):
offset = pars[-1]
g1 = gaussian(x, pars[0], pars[1], pars[2])
g2 = gaussian(x, pars[3], pars[4], pars[5])
g3 = gaussian(x, pars[6], pars[7], pars[8])
return g1 + g2 + g3 + offset
vel, flux = np.loadtxt('data.txt', unpack=True)
# Initial guesses for the parameters to fit:
# 3 amplitudes, means and standard deviations plus a continuum offset.
guess = [4, -50, 10, 4, 50, 10, 7, 0, 50, 1]
popt, pcov = curve_fit(multi_gaussian, vel, flux, guess)
plt.figure()
plt.plot(vel, flux, '-', linewidth=4, label='Data')
plt.plot(vel, multi_gaussian(vel, *popt), 'r--', linewidth=2, label='Fit')
plt.legend()
plt.show()结果
Stack Overflow用户
发布于 2020-05-24 22:02:46
scikit学习有一个GaussianMixtureModel的实现,它可以这样做。有关示例,请参见用户指南。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/54851012
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号